Jag tror att rätt många barn som nyligen har lärt sig läsa har gjort sina egna hemliga alfabet där det vanliga latinska/nordiska alfabetet ersätts med ”hemliga tecken” så att meddelandet blir oläsligt. Alternativt kan man använda Cesars kryptering där man tänker sig alfabetet som två ringar där man förskjuter den ena med ett visst antal steg. Om vi antar att vårt vanliga alfabet är den första ringen och vi vrider kryptoalfabetsringen tillbaka ett steg så får vi ett kryptoalfabet där
Vanlig text Krypterad text
a --> b
b --> c
osv.
Ett hemligt meddelande av denna typ är naturligtvis urenkelt att lösa. Med dator kan vi naturligtvis enkelt och snabbt testa alla kombinationer men också för hand går det snabbt att titta på tex. fördelningen av de vanligaste bokstäverna i det gissade språket i meddelandet vilket ger information om hur alfabetet skall förskjutas. Ett barns hemliga alfabet är likaså väldigt enkelt att läsa om vi har en vettig längd på meddelandet. Vi kan ur ordlängd etc. gissa bokstäver och rätt enkelt få fram det hemliga alfabetet.
Enkla substitutionsskiffer dvs. förskjutning av bokstäverna i alfabetet eller hemliga symboler i stället för det normala alfabetet är så enkla att lösa att man kan säga att ett meddelande som kodats på detta sätt egentligen endast visar att meddelandet inte är tänkt att läsas rakt upp och ner.
En intressant detalj är Stanley Kubricks film ”Ett rymdäventyr 2001” där skeppets tänkande dator heter ”HAL”. Av en slump 😉 så är HAL ordet IBM förskjutet en bokstav i riktning mot A d.v.s. IBM har kodats met ett Caesarskiffer försjutet endast ett steg i riktning mot A. Om man vill göra en textfil besvärlig att läsa men helt utan risk att man tappar lösenordet till texten så kan man koda en text med Unixverktyget rot13 som alltså förskjuter alfabetet med 13 steg. Säkerheten är lika med noll men det går inte att se vad texten innehåller bara genom att skumma av den med ögat.
Steganografi
Steganografi är tekniken att gömma ett meddelande tex inom ett skenbart oskyldigt meddelande. Antag att en medeltida krigsherre börjar ha slut på krutet och skickar ett meddelande till den egna kungen där han ber om 1500 kaggar fläsk, 20 kärror bröd … och på slutet konstaterar han krigståget måste avbrytas om han inte snabbt får mera mjöl, smör och salt … där den hemliga betydelsen kunde vara ‘mjöl=kol’, ‘smör=svavel’ och ‘salt=salpeter’ (de tre ingredienserna i svartkrut).
Under antiken kunde en kung t.ex. skicka en slav med ett hemligt meddelande så att håret rakades av huvudet på slaven varefter meddelandet skrevs på skalpen. Då håret hade vuxit ut skickades slaven till mottagaren som rakade av håret igen och läste meddelandet. Andra alternativ kunde vara att lägga in ett meddelande i ett bakat bröd … alternativen är många.
Vi såg i föregående inlägg hur man kan generera morsekod med hjälp av ett dataprogram. Ett kort meddelande, några ord, går på kanske 20 sekunder och ljudfilens längd är ungefär en miljon tecken. Antag att jag, den hemliga agenten, vill skicka en femsidig rapport till min uppdragsgivare utan att väcka uppmärksamhet. Jag kan då ta i bruk mitt morseprogram och regelbundet under en tid skicka t.ex. hälsningar till olika personer med morse. Meddelandet byts med någon dags mellanrum och fienden tittar på varje meddelande … men hittar inget.
Jag har redan tidigare, med tanke på användning för steganografi, modifierat både ljudfilerna och pauserna jag använder för att bygga upp meddelandena så att det finns brus i signalerna t.ex. med toppvärdet ungefär 8- bitar av den 16 bitars amplitud ljudfilen tillåter. Bruset ligger då på ungefär 0.5% vilket inte är speciellt störande.
Antag att jag vill skicka min rapport som innehåller 10000 tecken inbakad i morsesignalen. Min text består av tecken som alla ryms i en byte (8 bitar) som i sin tur ryms inom bottenbruset i min morsesignal. Jag behöver nu endast via någon annan kanal meddela min uppdragsgivare att ”Kom ihåg att gratulera den brittiska drottningen då hon fyller 100 år”. Hundra i detta meddelande betyder att jag byter ut vart hundrade talvärde i bruset i meddelandet mot en bokstav. Bruset kommer att öka marginellt men inte så att man enkelt hör skillnaden. Jag måste då skriva ett morsemeddelande som producerar en morse wav-fil med längden större än en miljon talvärden … enkelt.
Jag lägger ut den mixade morsefilen på den vanliga platsen för min morsehobby och min uppdragsgivare laddar ner filen och kör ett program som plockar ut vart hundrade talvärde i wav-filen och dumpar resultatet i en textfil som är min återskapade rapport.
Jag har alltså dolt en textrapport på 10000 tecken i ett oskyldigt morsemeddelande som gick på kanske 20-30 bokstäver. Notera att den sända dolda texten naturligtvis i sig kan vara krypterad innan den läggs till bruset i morsekoden. Det är naturligtvis självklart att texten inte behöver läggas in med 100 teckens intervall utan jag kan använda en slumptalsgenerator som genererar en lämplig slumptalssekvens som säger hur långt avståndet är mellan det hemliga dokumentets bokstäver. Det är också sannolikt att jag endast vill lägga in text i bruset i pauser inte i den reguljära sinusvågen jag använder som ljud eftersom det kan verka misstänkt in enstaka sampel ligger mycket nära noll då sinusvågen ligger nära ett. Jag kan hoppa över områden där jag har en morseton. Både jag och min uppdragsgivare måste naturligtvis kunna generera samma sekvens. Det är självklart att det enkelt går att gömma stora mängder text i en ljudfil som ovan men också självklart att det krävs en del funderande över hur man bäst döljer att det ligger ett meddelande inbakat i filen.
Bilden visar ljusrött brus med amplituden 0.125 (signalen har amplituden 1.0). Om vi antar att ljudfilen är kodad som 16-bitars PCM så kan vi lägga in data med ett största värde 8192 utan att vårt hemliga meddelande sticker ut på något sätt.
Digitalbilder innehåller också enorma mängder data. En modern digitalkamera producerar bilder vars storlek är tiotals megabyte d.v.s. tiotals gånger större än morseljudfilen. Varje bildpunkt innehåller information om tre olika färger och varje färg kodas i en eller flera byte. Det är självklart att jag kan koda information, om jag så vill i pixlar i bilden t.ex. så att jag modifierar färgdata så att jag modifierar en färg så att om färgens värde är ”jämnt” d.v.s. 2, 4, 6 … 254 så skall färgen tolkas som en etta d.v.s. en bit med värdet = 1. På motsvarande sätt kan jag koda en nolla så att jag modifierar ett färgvärde till ”udda” som då tolkas som en bit=0. Förändringarna jag behöver göra är extremt små och sannolikt odetekterbara speciellt som mitt meddelande matar in varierande bitar. Slutresultatet är en bild som ser helt normal ut men i vilken jag kan koda in mängder av dolda data. Olika typer av steganografiska metoder används idag till att koda in t.e.x. copyright information i bilden vilket gör att det i efterhand går att bevisa vem som ägde rättigheterna till bilden.
Notera att det inte är självklart att ovan beskrivna kodningar överlever packning. Om jag konverterar min morse ljudfil till mp3 formatet så kommer filen att packas ihop betydligt. En mp3 kodning är inte förlustfri vilket betyder att om jag packar upp filen tillbaka till wav så har sannolikt mitt hemliga meddelande också förstörts. Samma princip gäller bilder. Enkla hemliga kodningar kan förstöras av packning till något icke förlustfritt format.
En motståndare som försöker hitta mina dolda meddelanden skulle sannolikt bli mycket misstänksam om jag ibland skulle skicka mp3 morsemeddelanden och andra gånger wav meddelanden. Lösningen skulle naturligtvis vara att alltid skicka wav-filer som är opackade.
I tidigare inlägg har jag visat hur man automatiskt kan översätta skriven text till morse och därefter generera en ljudfil som man t.ex. kunde köra igenom en radiosändare och om effekten är tillräckligt stark och reflexionerna i atmosfären optimala så kan man i princip höra morsemeddelandet överallt på jorden.
Vad gör jag om jag inte kan morse d.v.s. meddelandet är bara en okänd serie blippar. Kan jag skriva ett program som läser in morsekoden som ljud och översätter ljudmeddelandet till text? Det visar sig att detta, om signalen är optimal, är mycket enkelt att göra. Amplituden på alla ljudsignaler är exakt lika och alla pauser har någon av tre exakt definierade längder.
Signalen har följande utseende om jag tittar på ljudfilen med hjälp av programmet Audacity:
Vi ser att signalen är extremt ren och störningsfri. Pauser har ljudnivån noll helt utan något brus och signalen är en sinusvåg med konstant amplitud.
För att kunna läsa av signalen likriktar vi den först d.v.s. vi tar absolutvärdet av signalen så att alla negativa värden under strecket i figuren blir positiva. Signalen varierar våldsamt mellan 0 och ca. 0.5 och för att vi skall kunna bedöma om vi detekterar ljud eller tystnad filtrerar vi signalen så att vi beräknar medelvärdet av ett antal ljudvärden. Om medelvärdet är klart positivt så hör programmet ljud och då medelvärdet ligger mycket nära noll så är det tyst.
Programmet har en funktion/subrutin. Jag skrev denna gång programmet i språket python. Översättningen går till så att jag samlar ihop fragment av korta ljdsignaler (*) och långa ljudsignaler (-). Ljudsignalerna läggs till en textsträng ända tills vi stöter på en ”teckenpaus” d.v.s. en paus mellan bokstäver. Vi skickar nu textsträngen t.ex. ‘*-‘ till funktionen translate_char(tecken) som jämför morsetecknet med alla morsetecken i morsealfabetet och därefter skriver ut resultatet som bokstaven ‘a’ i detta fall. Vi nollar nu morsesträngen och börjar samla * rep – för följande tecken. För att läsa vad programmet gör så hoppar vi över funktionen translate_char och börjar läsa kommandoraden på vilken vi vill ha endast en parameter d.v.s. ljudfilens namn. Ljudfilen kan vara en mp3- eller en wav-fil. Om vi ger en mp3-fil så konverterar programmet automatiskt mp3 filen till en wav-fil eftersom wav-filen är lättare att hantera rent tekniskt.
#!/home/lasi/miniconda3/bin/python
# Name=morse_receiver.py
# The program reads an audio file and converts the audio back to plain text.
# The analysis works as follows:
# Read the message and record the lengths of sound and silence to a file.
# Determine the length of dots and dashes and the lengths of silence.
# Create a new file vith * - and the character interval + word interval.
# The file can now be analyzed for morse patterns and converted into text.
# This is free code. Use on your own risk.
import wavfile
import sys
import os
def translate_char(m_string):
m_string.strip()
if (m_string=="*-"):
return "A"
if (m_string=="-***"):
return "B"
if (m_string=="-*-*"):
return "C"
if (m_string=="-**"):
return "D"
if (m_string=="*"):
return "E"
if (m_string=="**-*"):
return "F"
if (m_string=="--*"):
return "G"
if (m_string=="****"):
return "H"
if (m_string=="**"):
return "I"
if (m_string=="*---"):
return "J"
if (m_string=="-*-"):
return "K"
if (m_string=="*-**"):
return "L"
if (m_string=="--"):
return "M"
if (m_string=="-*"):
return "N"
if (m_string=="---"):
return "O"
if (m_string=="*--*"):
return "P"
if (m_string=="--*-"):
return "Q"
if (m_string=="*-*"):
return "R"
if (m_string=="***"):
return "S"
if (m_string=="-"):
return "T"
if (m_string=="**-"):
return "U"
if (m_string=="***-"):
return "V"
if (m_string=="*--"):
return "W"
if (m_string=="-**-"):
return "X"
if (m_string=="-*--"):
return "Y"
if (m_string=="--**"):
return "Z"
if (m_string=="*--*-"):
return "Å"
if (m_string=="*-*-"):
return "Ä"
if (m_string=="---*"):
return "Ö"
if (m_string=="*----"):
return "1"
if (m_string=="**---"):
return "2"
if (m_string=="***--"):
return "3"
if (m_string=="****-"):
return "4"
if (m_string=="*****"):
return "5"
if (m_string=="-****"):
return "6"
if (m_string=="--***"):
return "7"
if (m_string=="---**"):
return "8"
if (m_string=="----*"):
return "9"
if (m_string=="-----"):
return "0"
# Primitive error check
print("Error m_string=",m_string)
print("Len=",len(m_string))
return "?"
if (len(sys.argv)<1) or (len(sys.argv)>=3):
print("Usage: morse_receiver.py snd_file")
exit(0)
# We only process wav-files. If I get a mp3 then convert it to wav
# Add further conversions here as nedessary.
# Filtypen bestäms utifrån filnamnet inte från magisk filtyp.
snd_file = sys.argv[1]
print("File to process: ",snd_file)
if snd_file.endswith('.mp3'):
print("MP3 file detected")
# Convert to a wav file
# model ffmpeg -i song.mp3 -ar 44100 song.wav
cmd = "ffmpeg -i "+snd_file+" -loglevel quiet -ar 44100 -y "+snd_file+".wav >/dev/null"
snd_file=snd_file+".wav"
print("Converted file="+snd_file)
# Convert the mp3 file to wav before processing.
os.system(cmd)
f = wavfile.open(snd_file, 'r')
frames=f.num_frames
wav_data=f.read_float(frames)
ampl=0
i=0
snd = False
nosnd = True
pstart=0
sstart=0
my_ch = "";
for d in wav_data:
ampl=(9*ampl+abs(d[0]))/10
i=i+1
if((ampl>0.1) and (nosnd==True)):
sstart=i
l = i-pstart
if(l<5000):
sp=0
elif((l>5000) and (l<20000)):
print(translate_char(my_ch)+" "+my_ch)
my_ch=""
else:
print(translate_char(my_ch)+" "+my_ch+"\n")
my_ch=""
snd = True
nosnd = False
elif((ampl<0.01) and (snd==True)):
pstart = i
if((i-sstart)<5000):
my_ch = my_ch + "*"
else:
my_ch = my_ch + "-"
snd=False
nosnd=True
Vi kontrollerar om vi fick en mp3-fil som parameter. Om detta är fallet så bygger vi upp ett kommando som en textsträng där programmet ffmpeg används för att göra en wav-kopia av mp3-filen. Kommandot utförs av det externa programmet ffmpeg genom att anropa det via system() d.v.s. vi gör inifrån programmet detsamma som vi skulle ha kunnat göra på kommandoraden.
if snd_file.endswith('.mp3'):
print("MP3 file detected")
# Convert to a wav file
# model ffmpeg -i song.mp3 -ar 44100 song.wav
cmd = "ffmpeg -i "+snd_file+" -loglevel quiet -ar 44100 -y "+snd_file+".wav >/dev/null"
snd_file=snd_file+".wav"
print("Converted file="+snd_file)
# Convert the mp3 file to wav before processing.
os.system(cmd)
Vi läser nu in hela ljudfilen i minnet, PDP11 skulle storkna i detta skede eftersom användarminnet skulle ta slut innan ens halva filen är läst … fint att ha lite mera minne i en modern dator! Vi skapar också några hjälpvariabler som vi behöver lite senare. Om jag skulle dekoda en fil på PDP11 så skulle jag läsa in data från skiva i stället för att ha filen i datorns minne. Att använda skiva i stället för minnet fungerar precis lika bra men hastigheten är kanske en tusendel jämfört med att jobba direkt mot minne. PDP11 från 1970-talet skulle tugga länge på en dekodning av en 20 sekunders ljudfil. Gissar någon minut.
Vi börjar nu läsa in värden, ett datavärde i taget från filen som alltså ligger i centralminnet (RAM) och beräknar ett flytande medelvärde över tio ljudvärden. Experiment visade att detta gav en pålitlig detektion. Jag är övertygad om att en annan filtrering skulle fungera lika bra. För en annan ljudfil genererad av en utomstående producemt så skulle vi antagligen behöve experimentera här.
for d in wav_data:
ampl=(9*ampl+abs(d[0]))/10
Vi går nu vidare och ser när vi stöter på ljud och lägger då på minnet vilket ljudvärde 0 … vi hade och kontrollerar samtidigt om vi går från noll (icke ljud) mot ljud (större än ca. 0.1). Vi kan nu skilja på en ljudpuls och en paus. Genom att vi lagrade start och slut på pulsen så kan vi genom subtraktion beräkna längden på en ljudpuls eller en paus. Om vi stötte på en kort ljudpuls så lägger vi till ‘*’ i slutet av variablen my_ch . Om vi stötte på en lång ljudpuls så lägger vi till ‘-‘. Om vi stötte på en mellanlång eller lång paus så vet vi att tecknet är färdigt för översättning. Om vi stöter på en riktigt lång paus så vet vi att ett ord har passerats och då skriver vi ett radbyte för att underlätta läsningen.
Hela detektorn har då följande utseende:
for d in wav_data:
ampl=(9*ampl+abs(d[0]))/10
i=i+1
if((ampl>0.1) and (nosnd==True)):
sstart=i
l = i-pstart
if(l<5000):
sp=0
elif((l>5000) and (l<20000)):
print(translate_char(my_ch)+" "+my_ch)
my_ch=""
else:
print(translate_char(my_ch)+" "+my_ch+"\n")
my_ch=""
snd = True
nosnd = False
elif((ampl<0.01) and (snd==True)):
pstart = i
if((i-sstart)<5000):
my_ch = my_ch + "*"
else:
my_ch = my_ch + "-"
snd=False
nosnd=True
Intresserade läsare kan lyssna på morsekoden nedan. Min reaktion på denna morsemottagare är egentligen att det visade sig vara mycket lättare att skriva mottagaren än jag hade väntat mig.
Om någon läsare vill skriva en mottagare för svårare morsekod t.ex. morsekod där alla tidsvärden varierar då en människa sänder morse så gissar jag att jag skulle spela in alla meddelanden. Därefter skulle jag skriva en dynamisk analysator som gissar längden på kort/långt ljud samt länden av pause. Dv.s. jag skulle mäta längden på alla tidsvärden separat för vatje fil.
En annan komplikation är att signalamplituden sannolikt skulle kunna variera rätt mycket. Även detta skulle kräva separat hantering så att gränsvärdet för ljud/tystnad skulle kunna väljas utgående från signalen i stället för att ges ett fast värde som i detta exemple.
En gammal traditionell morsesändare sänder morse via en radiosändare. Om vi går mer än hundra år tillbaka i tiden så kunde sändningen gå över en enda tråd d.v.s. mellan två punkter vilket är ganska begränsat … så långt tillbaka går vi dock inte.
Om jag vill skicka iväg ett meddelande till i princip hela världen så hur gör jag? Problemet är främst hur jag skall kunna lagra den skapade ljudfilen automatiskt på en åtkomlig plats ute på nätet. Jag hade ursprungligen tänkt mig att jag lagrar filen på spegling.blog men jag råkade ut för en del tekniska komplikationer då jag försökte göra detta automatiskt. Jag kom då på att jag har en urgammal blog http://www.kolumbus.fi/larsil som stöder ftp-protokoll. Jag kan alltså flytta morse ljudfilen till kolumbus servern med ftp på samma sätt som jag flyttade filen från PDP11 till min huvuddator deNeb.
Att flytta en nygenererad morse ljudfil till kolumbus betyder att jag kör ett skript send.ftp som automatiskt flyttar filen upp till kolumbus där den är ”synlig för hela världen”.
#!/bin/bash
HOST=www.kolumbus.fi
USER=xxxxxxxx
PASSWORD=xxxxxxxxxxxx
ftp -inv $HOST <<EOF
user $USER $PASSWORD
put morse_message.mp3
bye
EOF
echo "Cleaning system variables"
unset HOST
unset USER
unset PASSWORD
Orsaken till att jag använder unset HOST etc. är att jag inte vill att dessa systemvariabler skall bli liggande i maskinen trots att maskinen naturligtvis är skyddad. Utan unset kunde en person som har vägen förbi, och terminalfönstret är öppet, får reda på t.ex. kolumbusserverns användarnamn och password genom att ge kommandona:
echo HOST
echo USER
echo PASSWORD
För att översätta en textrad till morse och flytta resultatet till Internet ger jag följande kommandon:
./smorse.run
Skriv text att sända som morse:sssss lars silen sssss
Ord=sssss
s *** ti ti ti
s *** ti ti ti
s *** ti ti ti
s *** ti ti ti
s *** ti ti ti
Ord=lars
l *-** ti taa ti ti
a *- ti taa
r *-* ti taa ti
s *** ti ti ti
--- etc ...
Jag valde att omge namnet med 's' eftersom bokstanen 's' i morsealfabetet är '***' d.v.s. ti ti ti vilket är lätt att känna igen.
Flyttning till servern kolumbus:
./send.ftp
Connected to xxxxxxxxxxxxxxxxxxx
220 ProFTPD Server (Elisa Oyj FTP Service)
331 Password required for xxxxxxxx
230 User xxxxxxxx logged in
Remote system type is UNIX.
Using binary mode to transfer files.
local: morse_message.mp3 remote: morse_message.mp3
200 PORT command successful
150 Opening BINARY mode data connection for morse_message.mp3
226 Transfer complete
169291 bytes sent in 0.10 secs (1.6789 MB/s)
221 Goodbye.
Cleaning system variables
Läsaren kan lyssna på hur morsesändaren låter nedan:
I en tidigare artikel visade jag hur man rätt enkelt kan skapa ett verktyg som möjliggör att tex. barn kan programmera på sitt eget modersmål i detta fall svenska. Språket ”sv” och kompilatorn ”csv” förstår svenska nyckelord och kompileras i två steg. Det första steget producerar c-kod och det andra skedet kompilerar från c-språket till körbar maskinkod (se den tidigare artikeln).
Hela paketet i den tidigare artikeln inkluderande lex-programmet som sköter översättningen från sv till c går på några hundra rader kod. Hur mycket jobb kräver det att modifiera programmen så att de kör på en urgammal Unix samt vilka är de begränsningar som är av sådan art att ny design behövs?
Kända begränsningar i PDP11
En maskin från 1970-talet var konstruerad för en specifikt engelsk/amerikansk miljö utan någon tanke på yttre nationella alfabet. Bokstäverna ÅÄÖ kunde stödas men sällan problemfritt. Jag valde att helt enkelt lämna bort prickar över åäöÅÄÖ d.v.s. texten ser ut som mina handskrivna skoluppsater på 1960-70-talet.
Maskinen stöder inte ljud vilket betyder att sändaren måste modifieras. I praktiken betyder detta att ljudet genereras på en annan (modern) maskin. Morsekoden som sådan lagras i en textfil och flyttas automatiskt till en annan maskin som tolkar den färdiga koden och genererar ljud. Jag kunde skriva kod på PDP11 emulatorn som styr in/ut pinnar på Raspberry Pi men jag uppfattar inte detta vara värt besväret.
Oväntade små problem
Det första problem jag stötte på var att det program lex genererade från swe.lex –> lex.yy.c inte kompilerade på PDP11 trots att jag körde en lex version som hörde hemma i BSD 2.11. Vad hände?
Jag kom inte ihåg att enradiga kommentarer ”// … till slutet av rad” är ett nytt påhitt. Jag löste problemet genom att ta bort denna typ av kommentarer. Samma sak måste göras med morseprogrammet. Det är naturligtvis möjligt att definiera om swe.lex så att jag genererar den gamla typens kommentarer i stället för nya enradiga. Detta blir en övning för framtiden.
Urgamla versioner av C-språket deklarerar parameterlistor till funktioner på ett annat sätt än moderna versioner. Ett exempel på detta är om jag vill läsa in någon parameter från kommandoraden.
I modern C-kod skulle jag deklarera kommandoradsparametrar på följande sätt:
Samma modifikation som i det senare exemplet måste jag göra för alla funktionsanrop som har parameterlista.
Funktionen getline som finns färdig i stdio.h i moderna varianter av C-språket eller egentligen i moderna varianter av C-biblioteket. Denna färdiga funktion introducerades ungefär 2010 d.v.s. långt efter att man slutade uppdatera min BSD 2.11. Lösningen är naturligtvis att skriva funktionen själv. Jag utgick från boken ”The C Programming Language” av Brian W. Kernighan och Dennis M. Ritchie. Boken är en klassiker! Min nya funktion fick följande utseende i språket sv:
Jag märker att jag använde return i stället för returnera vilket dock är ok eftersom return i såfall faller igenom oöversatt vilket ger korrekt C-språk … Notera att parametrarna är deklarerade på gammalt vis. Notera hur man gör två saker samtidigt i upprepa-slingan. Jag läser in ett tecken ‘c’ och kontrollerar samtidigt att inte filen har tagit slut. Detta kallas bieffekt och är något man försöker undvika i de flesta programmeringsspråk eftersom bieffekterna kan ge upphov till programmeringsfel som kan vara besvärliga att hitta om en bit programkod t.ex. förutom en tydlig jämförelse också ändrar värdet på en variabel.
Programmet kompilerar
Jag plockar bort ljudrutinerna i programmet som kör på PDP11 d.v.s. aplay eftersom det inte finns något ljudstöd.
Då programmet kompilerar första gången vet jag att jag börjar vara nära målet. Provkörning visade att den text jag matade in via getline splittrades upp i ord helt korrekt men vid körning fick jag diverse skräp efter det sista ordet. Problemet berodde på funktionen strtok som delar upp en sträng i en serie segment separerade av en eller flera separatorer i den gamla versionen ville ha två separatorer d.v.s. mellanslag ‘ ‘ och radbyte. I den nya C-versionen behövdes endast mellanslag som separator.
Då kompileringen går igenom märker jag att det inte lönar sig att kompilera om swe.lex varje gång eftersom kompileringen av lex.yy.c till programmet sv tar kanske 20 sekunder i stället för en blinkning under Linux på min normala PC. Lösningen är naturligtvis att kompilera om sv endast då detta behövs.
Då jag kör morseprogrammet blir resultatet:
./smorse
Skriv text att sanda som morse:lasse skriver
*-**
*-
***
***
*
+
***
-*-
*-*
**
***-
*
*-*
+
Tecknet ‘+’ betyder att det är en lång paus på 0.7 sekunder mellan ord.
Morsesekvensen ovan skickar jag i stället till en fil s.morse som jag sedan kan skicka vidare till morsesändaren på en annan maskin d.v.s. min Linux PC. Jag skriver ett enkelt shellskript som kör morseprogrammet och automatiskt skickar resultatet med ftp till min Linuxmaskin.
echo "Enter the text to send:"
./smorse >s.morse
sh send.ftp
Skriptet send.ftp använder ftp som har diskuterats tidigare för att skicka filen s.morse till Linuxmaskinen. Skriptet send.ftp har följande utseende:
ftp -inv $HOST <<EOF
user $USER $PASSWORD
put s.morse
bye
EOF
Jag har definierat systemvariablerna HOST, USER och PASSWORD som jag behöver för att kunna logga in på Linuxmaskinen. Filen morse.txt läggs för närvarande hemkatalogen men jag ändrar detta senare till att peka in till en egen katalog för sändaren. Från linux kan jag sedan med hjälp av ett enkelt litet program skicka resultatet vidare med epost som text eller skicka ljudet vidare tex. med radio. Det var roligt att se att det var enkelt att automatisera ftp-funktionen på PDP11.
Jag skrev en enkel morsetolk/sändare som kontinuerligt väntar på meddelanden att sända på min bordsdator deNeb. Programmet är listat nedan. Jag skrev på skoj programmet i programspråket Python som idag är en väldigt populär ersättare till forntidens Basic. Programmet sender.py visar hur man i Python kan generera ljud men också hur man enkelt kan använda kommandon ur operativsystemet eller något annat program på maskinen. Jag anropar operativsystemet för att kontrollera om det har kommit in något nytt sändningsjobb från PDP11 och putsar i såfall bort det gamla meddelandet. Programmet aplay genererar ljud till högtalarna och programmet ffmpeg skapar en ljudfil innehållande hela ljudsekvensen med bättre tidsprecision än anropen till aplay. Det tar ett ögonblick att starta upp aplay vilket gör timingen inexakt. Det kompletta meddelandet finns i ljudfilerna morse_message.wav samt i den komprimerade filen morse_message.mp3 . Vill man spara utrymme kan kvaliteten sänkas betydligt utan att meddelandet blir oläsligt. De råa ljudfilerna är så stora att de inte ryms i PDP11 normala användarminne (ca. 400 kb då ljudfilerna är 1.7 MByte och den packade mp3 filen är 462 kByte. I en 30 Euros Raspberry Pi läser man utan att blinka in ljudfilerna och behandlar dem i minnet om detta behövs. På 1970-talets PDP11 skulle man ha kört från skiva till skiva och behandlat små minnessegment och successivt skrivit data till skiva eller magnetband.
#!/home/lasi/miniconda3/bin/python
# Modify the python used to match your system (first line). Check with "which python".
# Name=sender.py
# The program "sends" morse code produced by the PDP11
# and automatically transferred to deNeb by ftp.
# This program checks if the file s.morse exists and
# if that is the case sends the morse code, deletes the
# morse message and then starts looking for the next message
# Author: Lars Silen
# This is free code. Feel free to use or modify on your own risk.
import os
import time
from os.path import exists
run = True
def send_morse(line):
for i in range(0,len(line)):
if line[i]=='*':
os.system("aplay 0_1.wav")
os.system("aplay sp.wav")
os.system('echo "file 0_1.wav" >>wav_files.txt\n')
os.system('echo "file sp.wav" >>wav_files.txt\n')
elif line[i]=='-':
os.system("aplay 0_3.wav")
os.system("aplay sp.wav")
os.system('echo "file 0_3.wav" >>wav_files.txt\n')
os.system('echo "file sp.wav" >>wav_files.txt\n')
elif line[i]=='\n':
os.system("aplay cp.wav")
os.system('echo "file cp.wav" >>wav_files.txt\n')
elif line[i]=="+":
os.system("aplay wp.wav")
os.system('echo "file wp.wav" >>wav_files.txt\n')
while run:
os.system("rm wav_files.txt")
if exists("s.morse"):
os.system("rm s.morse.old")
os.system("rm morse_message.wav")
os.system("rm morse_message.mp3")
f=open("s.morse","r")
lines = f.readlines()
# print(lines)
for i in range(2,len(lines)):
send_morse(lines[i])
os.system("mv s.morse s.morse.old")
# Create a wav file containing the audio of the message
os.system("ffmpeg -f concat -i wav_files.txt -c copy morse_message.wav")
os.system("ffmpeg -i morse_message.wav -vn -ar 44100 -ac 2 -b:a 192k morse_message.mp3")
print("Generated audio message! Listen to: morse_message.wav or morse_message.mp3")
else:
print("Sleep 5 seconds")
time.sleep(5)
os.system("clear")
En intressant jämförelse mellan det ursprungliga morseprogrammet kompilerat via C till maskinkod är att man hör skillnad mod Pythonprogrammets direkta ljudgenerering. Pythonprogrammet kör hörbart långsammare vilket i sig är naturligt då Python är ett tolkat språk som kör kanske 20 ggr långsammare än kompilerad C-kod.
Jag brukar spela folkmusik på fredagarna inne i Helsingfors centrum och jag passade på att vandra kanske en kilometer tillsammans med en annan spelman för att titta på demonstrationen. Min personliga upplevelse var att det var folkfest och människorna var glada. Jag såg två personer som var ordentligt berusade vilket inte är mycket då det är fredag kväll. Den ena var en dam som var så berusad att hon inte hölls på benen och som behövde hjälp då hon ville sova ruset av sig i en snödriva. Den andra individen står på bilen i bilden nedan. Det var blixthalt på bilen och egentligen ett under att hen inte ramlade ner … det fanns naturligtvis vindrutetorkare som hen höll i … tvivlar på att de efter den behandlingen längre torkar speciellt bra.
Jag kommer i denna artikel att visa hur jag enkelt kan skapa en svenskspråkig variant av programmeringsspråket C, språket kallar jag sv och kompilatorn blir då csv. Notera att avsikten med denna övning är att illustrera hur enkelt det vore att erbjuda en nationell nybörejarplattform för unga programmerare. För att verifiera programspråket sv skriver jag ett program som läser in en textsträng och sänder resultatet som morsekod. Morsekoden visas också i textform. Följande steg blir att undersöka vilka förändringar jag behöver göra i koden för att programmet skall fungera på min emulerade minidator PDP11/70 som kör en gammal BSD Unix 2.11 från början av 1990-talet. Unix utvecklades i tiden på minidatorn PDP11 som klarade av att hatera flera användare på olika terminaler allt detta på en maskin med 4 MB (4 miljoner byte) minne. En modern hemdator har typiskt 2000 gånger mera minne … eller ännu mer.
Kompilering av ett program skrivet i sv görs på någon sekund. Jag kompilerar morsesändaren smorse.sv dock utan filtyp eftersom mitt kompileringsskript förenklas en aning om jag inte behöver kontrollera filtypen utan kan anta att användaren vet vad hen gör.
./csv smorse Källkod:smorse.sv Översättaren är definierad i swe.lex Kompilerar översätteren swe.lex till c-kod Kompilerar lex analysatorn till körbar maskinkod: sv Översätter sv-programmet smorse.sv till c-kod: smorse.c C-kod finns nu i smorse.c Kompilerar nu till körbar maskinkod! The executable is: smorse.run
Jag kan nu köra programmet med smorse.run
Notera att morsesändningen i ljudfilen är en annan än på skärmen ovan. En utmaning för lyssnare är att bena ut vad som sänts!
Texten nedan visar hur ”kompilatorn” för språket sv är konstruerad. Jag skriver därefter programmet smorse i språket sv för att verifiera att kompileringen fungerar. Notera att programmet på min Linux-dator genererar hörbar morsekod. PDP11 har inte ljudstöd varför jag tänker generera ett simulerat magnetband som huvuddatorn kan sända som ljud.
En elev som lär sig att programmera kommer att stöta på flera samtidiga utmaningar. Vid programmering dyker det upp nya begrepp såsom ”variabel”, ”fil”, ”adress” och många andra begrepp som inte är bekanta från vardagslivet. Eleven lär sig också ett nytt språk, mycket enkelt dock, som beskriver logiken i programmet. Det språk som ligger under de flesta programmeringsspråk idag är engelska. Om vi börjar undervisa tex. en 10-12 årig elev programmering så kan engelskan som sådan vara ett visst problem som kan göra det svårare för eleven att komma över den första tröskeln in i programmeringens värld.
En enkel lösning på problemet programmering på ett främmande språk är naturligtvis att vi i inledningsaskedet skulle låta eleverna programmera på svenska/finska/norska/estniska för att därefter då grunderna finns gå över till engelska som idag är en de facto standard.
Skulle programmering på t.ex. svenska kräva våldsamma ekonomiska resurser? Är inte utveckling av ett nytt programmeringsspråk samt kompilator för det ”nya” språket extremt dyrt? Svaret är att en enkel tvåstegskompilator kan skrivas i ungefär hundra rader kod … inte dyrt alltså!
Om någon läsare är intresserad av att experimentera med språket sv eller modifiera det för något annat språk så kan det löna sig att ta kontakt via en kommentar så skickar jag alla filerna som ett paket med epost. Jag gör inte dessa förfrågningar synliga. Programlistningar på vebben tenderar att vara opålitliga vilket kan leda till onödig felsökning om man kopierar koden direkt från skärmen.
Språket ”sv” samt kompilatorn ”csv”
Min emulerade PDP11/70 minidator kör idag på mitt arbetsbord och jag måste således hitta på något vettigt leksaksprojekt. Jag kör BSD Unix v2.11 på PDP11:an vilket betyder att jag har tillgång till i princip samma programmeringsverktyg som på min huvuddator d.v.s. en kompilator för språket ”c” (kompilatorn heter cc) samt verktyget lex (lex har jag använt mycket sällan).
Ett trevligt miniprojekt kunde då vara att skapa ett svenskt programmeringsspråk som strukturellt är identiskt med programmeringsspråket ”c” under Unix/Linux. Tanken är att det skall vara möjligt att koda helt i ”sv” eller koda i en hybridmiljö där det är möjligt att använda ”c” direkt utan att programmets funktion påverkas. Tanken är att översätta ”sv” till normalt ”c” som därefter kompileras till maskinspråk som vilket normalt c-program som helst.
Fördelen med att använda c som mellanliggande språk är naturligtvis at jag inte behöver skriva den egentliga kompilatorn och maskinkodsgeneratorn (jag har för många år sedan skrivit ett komplett programmeringsspråk ”sil=simple language). Problemet är alltså att skriva en översättare från språket sv till språket c.
Unix ger tillgång till två klassiska verktyg för att skapa kompilatorer lex (lexical analyzer) och yacc (yacc=yet another compiler compiler). Jag har aldrig tidigare aktivt använt någondera. Programmet ”lex” kan enkelt sköta översättningen från sv till c d.v.s. jag behöver inte yacc eftersom min kompilator redan finns under förutsättning att det program lex producerar förmår att skapa kompilerbar c-kod.
Jag definierar ett antal ”REGLER” i lex som beskriver hur t.ex. ett nyckelord, en kommentar, en textsträng o.s.v. definieras. Då en regel passar in på källtexten skriver mitt genererade analysatorprogram ut motsvarande element för språket c.
Då jag skriver min översättare från sv till c i lex blir programmets längd ungefär hundra rader kod d.v.s. programmet är väldigt litet och överskådligt. Mitt sv-språk är i detta skede ett subset av språket c men redan i nedanstående form kan man skriva riktiga program i sv. Språket kan enkelt utvidgas genom att modifiera filen swe.lex. Då jag använder lex för att kompilera min definition av sv blir resultatet ett c-program som heter lex.yy.c . Jag kompilerar därefter lex.yy.c till ett körbart program sv som sköter översättningen av en källkodsfil i sv till motsvarande c-program.
Lex-program för översättning av sv till c
Filen swe.lex kan enkelt modofieras så att en större del av c-språket stöds. Notera att jag har skrivit swe.lex så att resulterande c-filen som ett sv-program översätts till har exakt samma antal rader som källkoden i sv. Detta betyder att då jag kompilerar mitt sv program så stämmer radnumren för felmeddelanden för både sv och c.
Min definition av sv-språket ser ut på följande sätt:
%{
/* A lexical analyzer for the computer language "sv". This is a simple translation */
/* of the "c" language into swedish. The corresponding "compiler" translates a */
/* sv-source into c-language that can be compiled using an ordinary c-compiler */
/* need this for the call to atof() below */
#include <math.h>
/* need this for printf(), fopen() and stdin below */
#include <stdio.h>
%}
WHITESPACE [ \t\n]+
DIGIT [0-9]
ID [a-zA-Z][a-zA-Z0-9]*
CHAR [a-zåäö][A-ZÅÄÖ][0-9][\ ][!?][\n]
COMMENT \/\/.*[\n]
STR1 \".[\\]*\"
APP [\"]
LPAR [(]
RPAR [)]
LWAV [{]
RWAV [}]
TERMINATOR [;]
EXCL [!]
AE [Ä]
ae [ä]
Aring [Å]
aring [å]
COMMA [,]
%%
{DIGIT}+ printf("%d",atoi(yytext));
{DIGIT}+"."{DIGIT}* printf("%s", yytext);
{STR1} printf("%s",yytext);
{LPAR} printf("%s",yytext);
{RPAR} printf("%s",yytext);
{LWAV} printf("%s",yytext);
{RWAV} printf("%s",yytext);
{EXCL} printf("!");
{COMMA} printf(",");
#inkludera printf("#include");
#definiera printf("#define");
program printf("\nmain");
funktion printf(" ");
resultat printf("return ");
alternativ printf("switch");
valt printf("case ");
bryt printf("break");
om printf("if ");
medan printf("while");
upprepa printf("for");
annars printf("else ");
skrivf printf("printf");
skrivr printf("printf");
fskrivf printf("fprintf");
hämtarad printf("getline");
hämta printf("get");
sätt printf("put");
läs printf("read");
läsrd printf("readln");
dröj printf("delay");
heltal printf("int ");
tecken printf("char ");
byte printf("byte ");
sanningsvärde printf("boolean ");
register printf("int");
bitmask printf("int");
likamed printf("==");
mindre_än printf("<");
mindre_än_eller_likamed printf("<=");
större_än printf(">");
större_än_eller_likamed printf(">=");
och printf("&&");
binär_och printf("&");
and printf("&");
or printf("|");
xor printf("^");
binär_exclusiv_och printf("^\n");
vflytta printf("<<");
hflytta printf(">>");
storlek_t printf("size_t");
\<\< printf("<<");
\>\> printf(">>");
= printf("=");
\< printf("<");
\> printf(">");
\. printf(".");
\&\& printf("&&");
\& printf("&");
{ID} printf("%s", yytext);
{TERMINATOR} printf("%s",yytext);
{COMMENT} printf("%s",yytext);
{WHITESPACE} printf("%s",yytext);
"+"|"-"|"*"|"/" printf("%s", yytext);
"{"[^}\n]*"}" /* eat up one-line comments */
%%
int main(int argc, char *argv[])
{
++argv, --argc; /* skip over program name */
if (argc > 0)
yyin = fopen(argv[0], "r");
else
yyin = stdin;
yylex();
return(0);
}
Verifiering av språket ”sv”
Ett enkelt sätt att visa att det nya språket ”fungerar” är naturligtvis att skriva ett riktigt program i programspråket sv. Jag byggde för kanske tjugo år sedan några led-ficklampor med några barnhemsbarn där vi använde en liten mikroprocessor som programmerades i mitt språk ”sil” (simple language) för Microchips processor 16F84. Ficklamporna programmerades så att de olika barnens ficklampor kunde blinka ägarens namn i morsekod.
Nedan visar jag hur man kan skriva ett program i språket sv som läser in en textrad från användaren och ”sänder” texten som morsekod till skärmen men också som morseljud via datorns högtalare. Jag kommer att flytta programmet till PDP11 och något modifiera det så att PDP11 som saknar högtalare i stället skickar ett magnetband till huvuddatorn för sändning, detta beskrivs eventuellt i en senare artikel.
Morsesändare skriven i sv
En morseöversättare gör man enklast så att man tabellerar tecknen ”A-Z”, ”a-z” samt siffrorna 0-9 samt deras motsvarande teckenkoder. För en specifik bokstav vill vi alltså ha en översättarfunktion skrivMorse() av ungefär följande typ (ti=’*’ och taa=’-‘):
heltal skrivMorse(tecken c){ heltal i; tecken morse[16]; alternativ (c){ valt ‘a’: strcpy(morse, ”-”); bryt;
valt ‘b’: strcpy(morse,”-”); bryt; valt ‘c’: strcpy(morse,”–”); bryt; valt ‘d’: strcpy(morse,”-”); bryt; valt ‘e’: strcpy(morse,”*”); bryt; … } skrivf(”Morsekod:%s\n”,morse); …
Som indata till vår funktion ”skrivMorse” ges ett tecken/en bokstav ”c” vid anrop till funktionen. Resultatet av översättningen finns efter exekvering nu i variabeln ”morse”. Jag antar att funktionen är ganska läslig även för personer som inte kan programmera. Nyckelordet ”bryt” betyder att rätt alternativ hittades och exekveringen fortsätter vid ”skrivf(…). Om vi vill översätta bokstaven ”s” till morse så anropar vi vår funktion med:
skrivMorse(‘s’);
Resultatet skulle bli Morsekod:***
Vi börjar vårt egentliga program med att låta programmet be om en text att sända samt läsa in en textrad som innehåller texten. Funktionen skrivf() skriver ut text som kan formatteras för heltal, flyttal etc. Vi kan göra detta med:
skrivf(”Skriv text att sända som morse:”); l=hämtaRad(&line,&len,stdin);
Kommandot ”hämtaRad” använder biblioteksfunktionen ”getline” som finns definierad i biblioteket stdio.h. Vi måste då komma ihåg att deklarera att vi använder biblioteket stdio.h . Vi inkluderar ett standardbibliotek med:
#inkludera <stdio.h>
Vårt program har nu ungefär följande utseende och det utför inte ännu något vettigt :
#inkludera <stdio.h>
#inkludera <stdlib.h>
#inkludera <string.h>
heltal skrivMorse(tecken c){ heltal i; char morse[16]; alternativ (c){ valt ‘a’: strcpy(morse, ”-”); bryt; valt ‘b’: strcpy(morse,”-**”); bryt; … fler definitioner av morsekoder … } }
heltal program(){ heltal l=0; storlek_t len=0; tecken *rad=NULL; skrivf(”Skriv text att sända som morse:”); l=hämtarad(&rad,&len,stdin); // Skriv ut den lästa raden för att verifiera att inläsningen lyckades skrivf(”Inläst rad:%s\n”,rad); }
Variablerna l, len och *rad behövs för anropet till hämtarad().
Då vi skriver in vår text som skall skickas så vill vi gärna hantera texten ordvis d.v.s. vi skickar ett ord i taget och genererar en standardiserad paus mellan orden. För att splittra up vår textsträng i separata ord inkluderar vi biblioteket string (#inkludera <string.h> se ovan). String-biblioteket har en användbar funktion strtok() som splittrar upp den text vi ger som funktionsparameter i en tabell med separata textsträngar (ordsträngar) separerade med mellanslag ‘ ‘. Råtexten bryts alltså vid mellanslag. Jag splittrar upp den ingående råtexten genast då jag deklarerar ordtabellen som jag kallar ett_ord:
tecken *ett_ord = strtok(rad,” ”);
Om jag har matat in texten ”Lasse skickar morse” så kommer ett_ord efter anrop att innehålla textsträngar som jag kommer åt med:
Vi kan nu skriva en ny funktion som vi kallar skicka_text_som_ord(”någon text …”) .
heltal skicka_text_som_ord(tecken rad[]){ heltal i; tecken *ett_ord = strtok(rad,” ”); medan (ett_ord != NULL){ skrivf(”Ord=%s\n”,ett_ord); upprepa(i=0; i<strlen(ett_ord);i++){ // Skriv ett tecken i nuvarande ord skrivMorse(ett_ord[i]); system(teckenpaus); skrivf(”\n”); } skrivf(”\n”); ett_ord = strtok(NULL, ” ”); } }
Efter att vi splittrade upp råtexten i ord så tar vi ett ord i taget och splittrar upp det i bokstäver som skickas för konvertering till morse.
Vi går igenom alla orden i vår råtext med:
medan (ett_ord != NULL){ skrivf(”Ord=%s\n”,ett_ord); … }
Motsvarande konstruktion i språket c är ”while(ett_ord != NULL){ … }” . Vi skickar vidare orden för sändning så länge som ett_ord inte är tomt (NULL).
Vi lägger nu till en slinga för att skicka iväg varje ord bokstav för bokstav för översättning till morse och sändning. Slingan har följande utseende:
upprepa(i=0; i<strlen(ett_ord);i++){
// Skriv ett tecken i nuvarande ord
skrivMorse(ett_ord[i]);
system(teckenpaus);
skrivf("\n");
}
Vi använder konstruktionen ”upprepa” som motsvarar c-språkets ”for” slinga. Slingan går igenom ordsträngen ett_ord bokstav för bokstav tills vi har nått den fulla längden på strängen ett_ord.
Slingan stegar alltså igenom ett_ord på följande sätt:
i=0 ett_ord[i] = ‘L’ som skickas till skrivMorse(‘L’) i=1 ett_ord[i] = ‘a’ som skickas till skrivMorse(‘a’) i=2 ett_ord[i] = ‘s’ som skickas till skrivMorse(‘s’) i=3 ett_ord[i] = ‘s’ som skickas till skrivMorse(‘s’) i=4 ett_ord[i] = ‘e’ som skickas till skrivMorse(‘e’)
Efter att vi har skickat ett helt ord så håller vi paus genom att anropa operativsystemets funktion sleep.
Vi låter systemet sova i 0.7 sekunder mellan ord. Sovtiden mellan bokstäver är 0.1 sekunder.
Vi spelar upp ”tit” och ”taa” under Linux så att jag med hjälp av programmet ”Audacity” genererade en ton med frekvensen 880 Hz. Från denna ton klippte jag två stumpar 0.1 repektive 0.3 sekunder långa som jag sparade som ljudfilerna 0_1.wav samt 0_3.wav . Jag kan spela upp en wavfil under Linux med hjälp av programmet ”aplay”.
Programmet i dess helhet (under linux i detta skede) har då följande utseende:
// Morse
// Programspråket "sv" är språket "c" med svenska kommando-ord.
// Språket översätts till standard "c" som sedan kompileras till maskinspråk
// för att köras.
// Språket "sv" är egentligen ett experiment med Unixverktyget "lex" som
// har konstruerats för att känna igen ord och strukturer i en text.
// Strukturer som hittas skulle normalt skickas vidare till programmet "yacc"
// (yet another compiler compiler = en annan kompilator kompilator).
// Eftersom jag översätter språket "sv" till "c" så behöver jag inte
// någon kompilator eftersom denna redan finns och likaså behöver jag inte
// någon kodgenerator som skulle generera maskinspråk eftersom även den redan
// finns. Notera att jag kan använda c-språk direkt om motsvarande
// sv-konstruktion inte har definierats.
// Notera att endast en delmängd av SV-C har skrivits.
// Vill man ha en mera fullständig
// motsvarighet så måste filen swe.lex utvidgas med nya nyckelord.
// Jag kör för närvarande en emulerad minidator PDP11/70 från 1970-talet.
// Operativsystemet är BSD Unix 2.11.
// Detta är ett experiment i att skriva ett enkelt svenskt
// programmeringsspråk som är körbart på denna urgamla dator.
//
// Lars Silen 2022
// Detta är öppen källkod som fritt får distribueras
// Författaren tar inget ansvar för eventuella fel i genererad kod
#inkludera <stdio.h>
#inkludera <stdlib.h>
#inkludera <string.h>
// Definiera tidslängden på olika element i Morse
tecken teckenpaus[] = "sleep 0.1";
tecken ordpaus[] = "sleep 0.7";
heltal skrivMorse(tecken c){
heltal i;
char morse[16];
alternativ (c){
valt 'a': strcpy(morse, "*-"); bryt;
valt 'b': strcpy(morse,"-***"); bryt;
valt 'c': strcpy(morse,"-*-*"); bryt;
valt 'd': strcpy(morse,"-**"); bryt;
valt 'e': strcpy(morse,"*"); bryt;
valt 'f': strcpy(morse,"**-*"); bryt;
valt 'g': strcpy(morse,"--*"); bryt;
valt 'h': strcpy(morse,"****"); bryt;
valt 'i': strcpy(morse,"**"); bryt;
valt 'j': strcpy(morse,"*---"); bryt;
valt 'k': strcpy(morse,"-*-"); bryt;
valt 'l': strcpy(morse,"*-**"); bryt;
valt 'm': strcpy(morse,"--"); bryt;
valt 'n': strcpy(morse,"-*"); bryt;
valt 'o': strcpy(morse,"---"); bryt;
valt 'p': strcpy(morse,"*--*"); bryt;
valt 'q': strcpy(morse,"--*-"); bryt;
valt 'r': strcpy(morse,"*-*"); bryt;
valt 's': strcpy(morse,"***"); bryt;
valt 't': strcpy(morse,"-"); bryt;
valt 'u': strcpy(morse,"**-"); bryt;
valt 'v': strcpy(morse,"***-"); bryt;
valt 'w': strcpy(morse,"*--"); bryt;
valt 'x': strcpy(morse,"-**-"); bryt;
valt 'y': strcpy(morse,"-*--"); bryt;
valt 'z': strcpy(morse,"--**"); bryt;
// Lägg till ÅÄÖ här om du behöver dem
valt 'A': strcpy(morse, "*-"); bryt;
valt 'B': strcpy(morse,"-***"); bryt;
valt 'C': strcpy(morse,"-*-*"); bryt;
valt 'D': strcpy(morse,"-**"); bryt;
valt 'E': strcpy(morse,"*"); bryt;
valt 'F': strcpy(morse,"**-*"); bryt;
valt 'G': strcpy(morse,"--*"); bryt;
valt 'H': strcpy(morse,"****"); bryt;
valt 'I': strcpy(morse,"**"); bryt;
valt 'J': strcpy(morse,"*---"); bryt;
valt 'K': strcpy(morse,"-*-"); bryt;
valt 'L': strcpy(morse,"*-**"); bryt;
valt 'M': strcpy(morse,"--"); bryt;
valt 'N': strcpy(morse,"-*"); bryt;
valt 'O': strcpy(morse,"---"); bryt;
valt 'P': strcpy(morse,"*--*"); bryt;
valt 'Q': strcpy(morse,"--*-"); bryt;
valt 'R': strcpy(morse,"*-*"); bryt;
valt 'S': strcpy(morse,"***"); bryt;
valt 'T': strcpy(morse,"-"); bryt;
valt 'U': strcpy(morse,"**-"); bryt;
valt 'V': strcpy(morse,"***-"); bryt;
valt 'W': strcpy(morse,"*--"); bryt;
valt 'X': strcpy(morse,"-**-"); bryt;
valt 'Y': strcpy(morse,"-*--"); bryt;
valt 'Z': strcpy(morse,"--**"); bryt;
// Lägg till åäö här om du behöver dem
valt '1': strcpy(morse,"*----"); bryt;
valt '2': strcpy(morse,"**---"); bryt;
valt '3': strcpy(morse,"***--"); bryt;
valt '4': strcpy(morse,"****-"); bryt;
valt '5': strcpy(morse,"*****"); bryt;
valt '6': strcpy(morse,"-****"); bryt;
valt '7': strcpy(morse,"--***"); bryt;
valt '8': strcpy(morse,"---**"); bryt;
valt '9': strcpy(morse,"----*"); bryt;
valt '0': strcpy(morse,"-----"); bryt;
// Lägg till skiljetecken etc här
}
// Skriv bokstaven som sänds (finns som variabelparametern "c" vid anropet)
skrivf("%c ",c);
skrivf("%s ",morse);
// Generera ljud
upprepa(i=0; i<strlen(morse);i++){
om (morse[i] == '*'){
skrivf("ti ");
system("aplay -q 0_1.wav >/dev/null");
} annars {
skrivf("taa ");
system("aplay -q 0_3.wav >/dev/null");
}
// skrivf("\n");
}
}
heltal skicka_text_som_ord(tecken rad[]){
heltal i;
tecken *ett_ord = strtok(rad," ");
medan (ett_ord != NULL){
skrivf("Ord=%s\n",ett_ord);
upprepa(i=0; i<strlen(ett_ord);i++){
// Skriv ett tecken i nuvarande ord
skrivMorse(ett_ord[i]);
system(teckenpaus);
skrivf("\n");
}
skrivf("\n");
ett_ord = strtok(NULL, " ");
}
}
heltal program(){
heltal l=0;
storlek_t len=0;
tecken *rad=NULL;
skrivf("Skriv text att sända som morse:");
l=hämtarad(&rad,&len,stdin);
skicka_text_som_ord(rad);
}
Den genererade c-koden är strukturellt identisk med sv-programmets kod d.v.s. vi gör en ord för ord översättning. Detta betyder att c-kompilatorn ger felmeddelanden som pekar till rätt rad också i sv källkoden. Min editor bör naturligtvis konfigureras så att den visar radnummer för att felsökning skall vara effektiv.
Översättaren bör sannolikt expanderas med ytterligare c-konstruktioner. Det är oklart i hur hög utsträckning det är värt att översätta funktioner i bibliotek men exemplet ”hämtaRad” visar att detta naturligtvis är möjligt. Det är naturligtvis också möjligt att översätta namnen på standardbiblioteken på samma sätt men knappast vettigt eftersom målet är att eleven också bekantar sig med c-språket och dess bibliotek.
Oversättarprogram komplett:
#!/bin/bash
# Name=csv
# Detta är en kompilator för programspråket "sv" som är en svensk översätytning av språket "c".
# Språket "sv" kan enkelt utvidgas genom att modifiera filen "swe.lex".
# Användning: ./csv program
# Notera att källkoden antas vara program.sv .
# Resultatet blir det körbara programmet program.run
#
# En textfil som är en översättning till språket "c" genereras som program.c .
# Lars Silen 2022
# Detta är fri källkod som fritt får användas och modifieras på egen risk.
echo "Källkod:"$1.sv
echo "Översättaren är definierad i swe.lex"
echo "Kompilerar översätteren swe.lex till c-kod"
lex swe.lex
echo "Kompilerar lex analysatorn till körbar maskinkod: sv"
gcc lex.yy.c -ll -o sv
echo "Översätter sv-programmet " $1.sv " till c-kod: " $1.c
./sv $1.sv >$1.c
echo "C-kod finns nu i " $1.c
echo "Kompilerar nu till körbar maskinkod!"
gcc $1.c -o $1.run
echo "The executable is:" $1.run
Notera att skriptet kompilerar om swe.lex varje gång. Användaren kan alltså enkelt lägga till nya definitioner som blir en del av språket. Om användaren uppfattar att språkdefinitionen är stabil så kan man naturligtvis lämna bort raderna lex swe.lex samt gcc lex.yy.c -ll -o sv , tidsvinsten blir dock marginell.
Vi har idag 31.1.2022 levt ungefär två år med COVID-19 och kontinuerlig missinformation från myndigheter och media. Notera att officiell missinformationen inte endast har levererats lokalt här i Finland utan samma problem ses globalt och synbarligen coordinerat eftersom samma ”nyheter” och samma lögner levereras samtidigt genom alla mediakanaler. Informationen man har tutat ut har använts för att motivera systematisk nedmontering av våra västerländska fri- och rättigheter. Man har använt en sjukdom som enligt tidigare Finsk definition på pandemi aldrig skulle ha uppfattats som en pandemi utan som en alvarlig influenssa. COVID-19 definierades av WHO som en pandemi varpå Finland som skoleleven som är bäst i klassen genast accepterade allt som kom från högre ort.
Vi har kunnat se hur media har byggt upp ett eget system för faktagranskning. Medias faktagranskning görs av personer som totalt saknar kunskap om frågorna, kunskapsnivån kan vara studerande eller journalist, men trots detta kan faktagranskarna utan problem deklarera att t.ex. en nobelprisvinnare är ute med osanning och inte vet vad hen talar om. Den viktiga frågan blir då vem som granskar faktagranskarna, om detta över huvudtaget görs, samt vem som finansierar faktagranskningen. I videon nedan Dr John Campbell har blivit faktagranskad av BBC med domen ”Falskt”. Allt Dr John Campbell hänvisar till är taget ur officiella brittiska källor och faktagranskarna kunde inte peka på något fel men stämpeln blev ”Falsk”. Intressant att se hur media aktivt brunsmetar icke önskad information. Det saken gällde var att ett krav på tillgång till hemlig information via Freedom of Information Act (FOIA) godkändes i Brittisk domstol. Den information man ville ha fram var hur många personer som hade dött av COVID-19 som egentlig dödsorsak, inte som bidragande dödsorsak bland tex. olika kroniska dödliga sjukdomar. Den officiella siffran, det finns flera officiella alternativ, låg på ca. 150 000 döda med COVID. FOIA domslutet grävde fram resultatet att ca. 17 000 hade dött av COVID. Den intressanta frågan är vilken proportionen i Finland är? Jag gissar att informationen kommer fram i all tysthet efter några år i Finsk mortalitetsstatistik och logiskt sett borde situationen se ungefär lika ut här. Jag har inte sett Finska data men det är självklart att dessa data måste existera, om inte så borde huvuden rulla …
I Finland har ungefär en person på 2400 fått svåra biverkningar av Pfeisers vaccin (källa Fimea 31.1.2022). För personer som har fått Moderna vaccin är risken för svåra biverkningar ca. en person på 2000 (källa Fimea 31.1.2022). En biverkning anges som allvarlig om den har lett till patientens död, livsfara, sjukhusvård eller till förlängd sjukhusvård, förorsakat permanent skada, försämrad funktion eller medfödd missbildning. Det är intressant att se hur informationen presenteras på Fimeas vebbsidor. Man konstaterar på ingångssidan att alla vacciner har biverkningar men att dessa biverkningar normalt är mycket lindriga. För att hitta riktiga data, inte officiellt tyckande, måste man gräva djupare. På nivå två (se källor nedan) hittar vi information om 3361 rapporter om allvarliga biverkningar på 8172797 givna vaccinationer. Risken för allvarlig biverkning är då ca. en svår biverkning på 2400 injektioner. Då jag gräver vidare i Fimeas datan nivå tre, hittar jag en Pdf-fil med biverkningar presenterade som ”alla” samt ”allvarliga” detta gäller alla organ hos vaccinerade. Nu har antalet allvarliga bieffekter plötsligt stigit till 9035 d.v.s. ungefär tre gånger högre än siffran på nivå två (notera Fimeas definition av svår bieffekt i fet stil ovan). Då jag tittar i Pdf-filen så är nu andelen allvarliga biverkningar ungefär en på 900 av givna injektioner. Om man antar att risken är slumpmässig och en person får tre injektioner så är risken för allvarlig biverkning alltså av storleksordningen en på 300 att patienten får en allvarlig biverkning.Hur skall jag kunna tro på något av det myndigheterna för fram då myndigheternas egna data visar att myndigheterna ljuger? Fimeas data ser ut på följande sätt för Pfeizer:
Det är intressant att notera att om en vaccination på 900 ger svåra biverkningar så stämmer detta väl överens med min ”back of the envelope” överslagsberäkning i en tidigare artikel där jag grovt uppskattade att att chansen att nålen går i en ven (d.v.s. blodåder) där den inte hör hemma grovt kan antas vara ca en på tusen. Betyder detta i såfall att svåra biverkningar uppträder varje gång en vaccination av misstag ges i en ven i stället för i muskeln där den hör hemma? Hela problemet är lätt att undvika genom att aspirera injektionen d.v.s. kolven dras försiktigt tillbaka en kort sträcka så att man kan se om det kommer blod isprutan. Blod indikerar att nålen är i en åder eller har gått igenom en åder. Resultatet blir då att en stor mängd vaccin snabbt förs ut i hela kroppen vilket gör att spikprotein kan bildas i stora mängder i nästan godtyckliga organ med svåra biverkningar som följd. Exempel på svåra biverkningar som med till visshet gränsande sannolikhet har lett till dödsfall hos toppidrottare är hjärtmuskelinflammation och inflammation i hjärtsäcken. Det som skulle ha varit smärta och svaghet i armmuskeln blev till en livshotande skada då hjärtmuskeln började producera spikprotein och angreps av immunsystemet. Hur kan myndigheterna påstå att om en vaccination på 900 ger svåra biverkningar så uppträder biverkningarna mycket sällan, är detta avsiktlig disinformation eller endast politisk enfald?
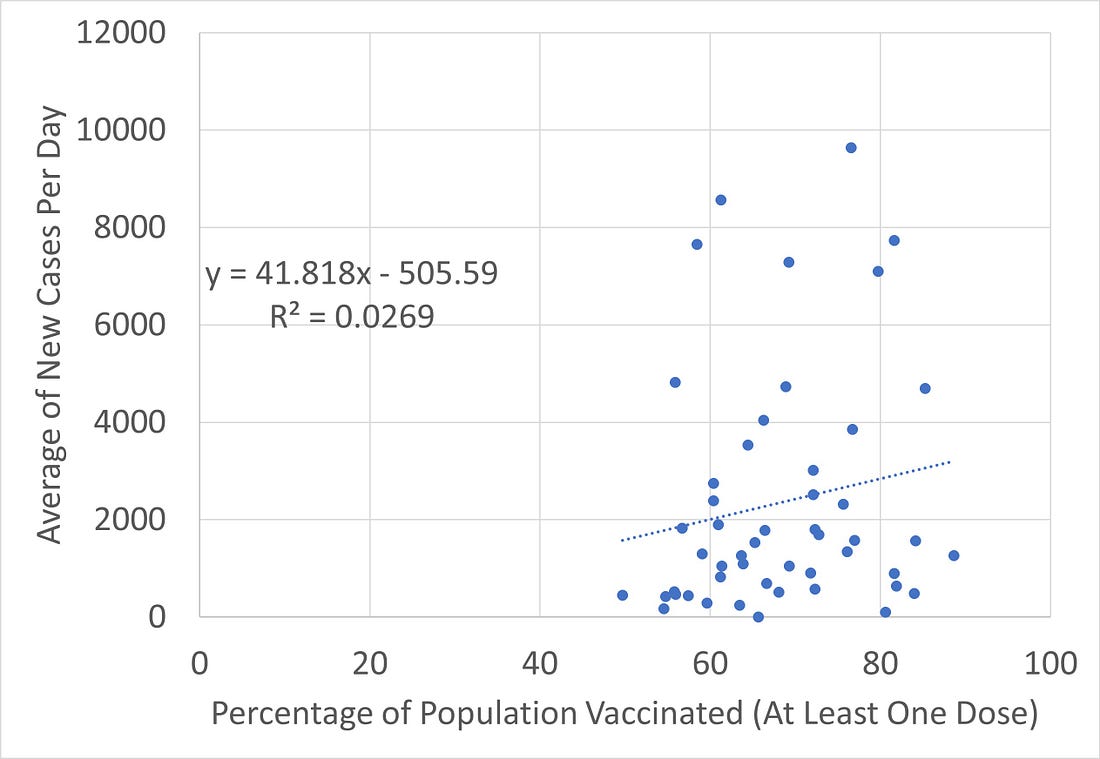
Tabellen ovan var på finska. För att kompensera detta hänvisar jag till Lars Berns blogg anthropocene.live där Bern ger en intressant bild av situationen i Israel (källa Our World in Data). Länken till lars Berns inlägg finns i källförteckningen nedan. Bilden visar klart att COVID-vaccinet är värdelöst. Ca. 90% av befolkningen är vaccinerad och sjukhusen fylls av vaccinerade.
Videon nedan är en allmän diskussion om vad som borde göras då vi helt klart börjar ha coviden bakom oss. Hur skall vi reagera för att nästa läckage från förbjuden forskning inte skall bli värre? Det börjar existera consensus på att COVID är läckage från ett laboratorium. Viruset är modifierat från ett fladdermusvirus så att viruset kan spridas mellan människor. Omikronvirusen, det finns två, verkar inte heller nödvändigtvis vara naturliga mutationer på de tidigare variationerna. Är också de här laboratorieexperiment? Har Omicron släppts av någon för att stoppa COVID-19 eller är det fråga om slump? Jag konstaterade själv i ett tidigt skede år 2020 att jag misstänkte att COVID är är en mänskligt skapad sjukdom. Mitt argument var att det finns publikationer som flera år innan COVID-utbrottet beskrev forskning kring modifikation av besläktade virus så att viruset skulle kunna spridas mellan människor (gain of function research). Videon är en lågmäld men sevärd diskussion mellan personer som vet vad de talar om.
Den 26.12.2021 skrev jag ett blogginlägg Autoimmuna reaktioner. Jag ställde där frågan att vad sker om de spikproteriner som syns på ytan av en cell som genom mRNA vaccin producerar spikprotein, triggar immunsystemet att förgöra ifrågavarande ”infekterade” cell då spikproteinet är främmande. Detta är det sätt på vilket immunsystemet borde fungera d.v.s. en enskild cell offras för helheten. Vad händer om immunsystemet samtidigt som den spikproteinsmittade cellen förgörs också lär sig att känna igen kroppsegna proteiner på/i cellen som länkade till det främmande spikproteinet. Kan man då tänka sig att kroppens immunsystem börjar angripa t.ex. muskelceller eftersom injektionen i första hand avses ges i muskeln inte intravenöst … Om kroppen triggas till att angripa egna celler så har man åstadkommit en autoimmun sjukdom. Om vanliga muskelceller nära injektionsstället angrips är det knappast något speciellt stort problem men om man genom en misslyckad injektion i en ven får stora mängder vaccin ut i kroppen så att spikproteiner bildas i tex. hjärtmuskeln så kan resultatet bli t.ex. hjärtmuskelinflammation.
Då man ser på armens uppbyggnad där injektionen ges, jag tänker då på den ungefärliga volymen av blodkärl i förhållande till muskeln. Vilken är chansen att vi träffar en större eller mindre ven inom detta område? Jag är fysiker, inte läkare, men jag uppfattar att chansen att träffa en blodåder egentligen är rätt stor d.v.s. av storleksordningen 1/1000. Träffas en ven vid injektionen så kommer betydande mängder mRNA material att snabbt transporteras till olika delar av kroppen vilket inte enligt vaccintillverkarna är avsikten. Vaccinet skall ges i en muskel, inte intravenöst. Problemet med okontrollerad spridning av vaccinet kan enkelt och extremt billigt åtgärdas genom aspirering innan vaccinet sprutas in i patienten. Vid aspirering dras sprutans kolv försiktigt tillbaka en liten bit. Om vi då ser blod komma in i sprutan så har vi träffat en blodåder och då måste vi försöka på nytt på en annan plats. Aspirering kostar ca. 5 sekunder extra tid men myndigheterna rekommenderar inte aspirering, varför?
Nedanstående video diskuterar det faktum att i hela den amerikanska armén har skett ca. 20 dödsfall i COVID-19 medan dödsfallen till följd av COVID-vaccination är betydligt högre. Läkaren konstaterar också prognosen för hjärtmuskelinflammation är att 66% avlider inom 5 år. Myocarditis är alltså inget obetydligt ”som en patient får en släng av” utan en allvarlig sjukdom som kan ge svåra bestående men.
En god vän skickade mig en länk till en intervju med Tamara Tuuminen. Videon under rubriken källor nedan uppfattar jag som informativ och det är helt klart att Tamara Tuuminen i detalj vet vad hon talar om. Videolänken går till tokentube.net eftersom youtube tydligen enligt känt mönster har bannlyst Tamara Tuuminen. Videon är intressant genom att den presenterar flera olika mekanismer för hur spikproteinen kan påverka cellkärnans DNA reparation, hur upprepade boosters kan påverka immunsystemet negativt etc. Notera att videon går på finska utan textning (beklagar).
Nedstängningar igen …
I Finland har man igen tagit beslut att stänga ner i stort sett all kultur samt många serviceyrken t.ex. restauranger är igen illa ute. Man motiverar nedstängningarna med att man vill garantera att sjukvårdens kapacitet skall räcka till. Samtidigt går propagandamaskineriet på högvarv för att vaccinera allt fler inklusive småbarn. I en diskussion på Meta=”Hon är död”/Facebook om bl.a. vacciners effekt presenterades nedanstående bild från Schweitz. Man kan diskutera hur man har kommit fram till bilden och också om den visar hela sanningen men låt oss acceptera den som sådan. Vi kan direkt ur bilden plocka ut dödsrisken för en ”ovaccinerad”.
Risken att dö i COVID, alla åldersdgrupper, för en ovaccinerad blir då:
Dödsrisk i procent: 100*13.06/100000= 0.013%
Detta betyder ett dödsfall på ungefär 7700. Är detta mycket?
För att kunna bilda oss en realistisk uppfattning om en dödsrisk på 1/7700 (0.013%) är hög eller låg så kan vi jämföra detta med ett normalt influenssaår där samma åldersgrupp d.v.s. 80+ normalt råkar illa ut och på slutändan dör i lunginflammation. Vi jämför de Schweitziska data i figuren ovan med influenssadöda i USA vintern 2017-2018 (se länk nedan). Vi betraktar tabell 1 i CDC rapporten. Ur tabellen kan vi för kombinationen alla ålderskategorier plocka ut ungefär motsvarande mortalitetsdata som för ovaccinerade som i figuren ovan. Vi hittar:
Dödsrisk i procent: 100*51646/41043550 = 0.126%
Detta betyder ungefär ett dödsfall på 800 d.v.s. risken för död under influenssasäsongen 2017-2018 låg på en nivå som var tio gånger (10x) högre än COVID-risken. Har hela samhället blivit galet?
Vaccination dödsrisk
I princip borde det finnas mycket material om biverkningar av vaccin. Ett exempel är det amerikanska VAERS registret. Problemet är att rapportering till registret verkar ske sporadiskt och okontrollerat. Det finns uppskattningar om att biverkningar underrapporteras med en faktor 41.
Om man inte kan lita på det register som borde samla information om COVID vaccinens biverkningar, vilka är då alternativen? Ett objektivt sätt är att studera dödligheten av alla orsaker bland ovaccinerade och vaccinerade. Om man ser oväntade förändringar i någondera gruppen borde varningsklockor ringa. New Zealand har, eftersom det är fråga om en ö där man mycket strikt har begränsat inresa från omgivande länder, kunnat hålla COVID smittograden på en mycket låg nivå samtidigt som man aktivt har gått in för omfattande vaccination av befolkningen. Frisk befolkning som vaccineras … hur ser överdödligheten ut tidsmässigt i förhållande till vaccinationerna?
Dr. Chris Martenson har intressanta data från New Zealand i videon nedan. Bilden visar vaccination och dödlighet i åldersgruppen 60+.
Totalt antal döda plottade över antalat givna vaccinationer. Antalat vaccinationer finns till vänster på Y-axeln och antalat döda till höger på Y-axeln. X-axeln är löpande datum från tidpunkten då vaccinationerna påbörjades.
Vi kan tydligt se hur dödligheten stiger med ökande vaccination. Korrelation är naturligtvis inte kausalitet men t.o.m. ett barn torde kunna se att vaccination och dödlighet på något sätt hänger ihop. Vi ser en ökad dödlighet, inte minskad som man skulle vänta sig. Vi kan försöka göra en uppskattning av vilken dödsrisken i ovanstående åldersgrupp är per given vaccination. Vid vaccinationstoppen är överdödligheten ungefär 650-525= 125. Antalet givna vaccinationer är ungefär 130 000. Notera att jag visuellt jämnar/filtrerar kurvorna. Vi är intresserade endast av en storleksordning för dödsrisken utgående från ovanstående data.
Dödsrisken i procent: 100*125/130000 = 0.1%
Notera att dödsrisken av vaccinationen ensam tydligen är ungefär jämförbar med influenssa men dödsrisken är tio gånger högre än den risk en ovaccinerad person som får covid utsätts för. Vilket är argumentet för att vaccinera åldersgrupper för vilka COVID inte utgör någon risk då själva vaccinet ensamt sannolikt medför en dödsrisk som är mångdubbelt större än risken vid genomliden sjukdom? Till detta kan ytterligare fogas att vi vet att COVID vaccinen inte hindrar en vaccinerad från att få COVID och det hindrar inte heller en vaccinerad från att sprida sjukdomen vidare. Vaccinens effekt på COVID-varianten Omicron verkar idag vara marginell. Varför överöses vi fortfarande av information om att vi måste vaccinera oss. Är det enfaldiga beslutsfattare som ligger bakom eller finns det någon annan agenda i botten?
En liten kommentar till den Schweiziska kurvan över dödsrisk för ovaccinerade och vaccinerade. Min uppfattning är att den stora skillnaden i dödsrisk mellan ovaccinerade och vaccinerade är en följd av att man definierar en vaccinerad person som en person som fått den andra sprutan minst två veckor tidigare. En person som fått sina två sprutor har alltså levt kanske 4-6 veckor med en vaccination och därefter ytterligare två veckor med två vaccinationer. Alla dödsfall inom denna grupp bokförs som dödsfall bland ovaccinerade. Detta är inte teori utan man kan se hur dödsfall bland ”ovaccinerade” i en åldersgrupp ökar då man inleder vaccination. Vilken är den logiska förklaringen till att dödsfallen ökar i den ovaccinerade referensgruppen. Svaret är helt enkelt att under den mest kritiska tiden efter en covid vaccination då risken för allvarliga biverkningar är störst så bokförs en person som ovaccinerad och dödsfall bokförs likaså i gruppen ovaccinerade.
Problemet med de Schweitziska data är att det är svårt att klassificera vad ett COVID dödsfall är. I Finland bokförs en person som COVID-död om hen har dött inom 30 dagar efter ett positivt coronatest d.v.s. trafikdödsfall, cancerdödsfall etc. bokförs som coronadöda om det finns ett positivt test i bakgrunden även om den egentliga dödsorsaken inte hade något att göra med covid.
Myndigheter som fungerar rationellt borde redan för en lång tid sedan ha stannat upp och ställt frågan: ”Vad är det som har förändrats? Varför verkar åtgärderna inte ha önskad effekt medan samhällsskadorna kan ses av varje vaken individ?”
Vilka är åtgärderna jag tänker på?
Försöket att med ”läckande” vaccin eliminera COVID har entydigt misslyckats. Idag smittas både relativt sett och absolut sett fler vaccinerade än ovaccinerade. Finns det något vettigt argument för att fortsätta att vaccinera andra än tydliga riskgrupper såsom åldringar, personer med nedsatt immunitet och personer med specifika underliggande sjukdomar?
Det finns idag mängder av indikationer på att flera vaccinationer med mRNA-vaccinerna kan ha en effekt som är motsatt den önskade d.v.s. antalet smittade i grupperna ovaccinerade, delvis vaccinerade och fullt vaccinerade är störst i gruppen fullt vaccinerade. Se grafen nedan från Ontario i Canada. Samma effekt har man redan länge kunnat se i Brittiska data. Notera att den vertikala skalan är antalet smittade per 100000 d.v.s. bilden är inte förvrängd av att majoriteten i samhället är vaccinerad. Det är intressant att notera att partiell vaccination tydligen har en viss positiv effekt men att tydligen flera vaccinationer på något sätt påverkar immunsystemet negativt.
EU:s EMA (European Medicines Agency) varnar för att återkommande vaccinationer (boosters) mot COVID kan leda till försämrad immunrespons. Min uppfattning är att detta är exakt det man ser i Canadensiska data i bilden ovan.
En grupp statistiker har gjort en statistisk jämförelse av effekterna av COVID vaccination på två variabler y1 som representerar dödlighet per miljon invånare och y2 som representerar smittade per miljon invånare. Resultatet i korthet verkar vara att:
Av de undersökta länderna visade ca. 89% (statistiskt signifikant) en ökad dödlighet kopplad till COVID-19 till följd av att man påbörjade vaccination. På motsvarande sätt visade ca. 87% (y2) en ökad smittograd per 100000 invånare till följd av påbörjad vaccination. Den causala effekten på y1 varierade mellan -19% och 19015% med ett medelvärde på +463% (notera att man förväntar sig att effekten av vaccination borde ge ett negativt resultat d.v.s. minskande total dödlighet). Effekten av vaccination på y2 (smittograden) varierade mellan -46 och 12240% med ett medelvärde på +261%.
Konklusionen är att den statistiskt signifikanta och dominerande positiva effekten d.v.s. dödlighet och smittograd ökar bör vara mycket oroande för beslutsfattare. Har beslutsfattarnas åtgärder på slutändan lett till ökad dödlighet och ökad smittograd?
Är vi idag i en situation där de samhälleliga åtgärderna för att bekämpa COVID gör situationen värre i stället för bättre? Några exempel:
James Lyons-Weiler studie gällande stater i USA. Ju högre vaccinationsgrad desto fler smittade.
En tysk studie av professorerna Rolf Steyer och Gregor Kappler från 16.11.2021 kommer till samma resultat för förbundsrepubliken Tyskland med följande sammanfattning:
Zusammenfassung
Die Korrelation zwischen der Übersterblichkeit in den Bundesländern und deren Impfquote bei Gewichtung mit der relativen Einwohnerzahl des Bundeslands beträgt .31. Diese Zahl ist erstaunlich hoch und wäre negativ zu erwarten, wenn die Impfung die Sterblichkeit verringern würde. Für den betrachteten Zeitraum (KW 36 bis KW 40, 2021) gilt also: Je höher die Impfquote, desto höher die Übersterblichkeit. Angesichts der anstehenden politischen Maßnahmen zur angestrebten Eindämmung des Virus ist diese Zahlbeunruhigend und erklärungsbedürftig, wenn man weitere politische Maßnahmen ergreifen will, mit dem Ziel, die Impfquote zu erhöhen.
En fri översättning (Lars Silen) är:
Sammanfattning
Korrelationen mellan överdödlighet i förbundsstaterna och vaccinationsgraden vägt med relativt invånartal i ifrågavarande förbundsstat ger värdet 0.31. Värdet är förvånande högt och det borde vara negativt om vaccination skulle minska dödligheten. Under observationstiden (veckorna 36-40 2021) gäller altså: Ju högre vaccinationsgrad desto högre är överdödligheten. Med tanke på de kommande politiska åtgärderna för att begränsa viruset är denna siffra oroande och kräver förklaring om ytterligare politiska åtgärder ska vidtas i syfte att öka vaccinationstäckningen.
Den ansedda medicinska tidskriften The Lancet konstaterar att 89% av dagens smittade med symtom är fullt vaccinerade notera att detta är en större andel än andelen vaccinerade d.v.s. vi ser igen att flera vaccinationer tydligen ökar risken att smittas. Se källa nedan.
The Exposé har en intressant artikel där man använder brittiska data (UKHSA Vaccine Surveillance Reports) och visar, på samma sätt som jag har gjort i tidigare inlägg, att vaccinens skyddseffekt snabbt minskar. Det verkar rätt klart att en boosterdos temporärt ger ett bättre skydd mot COVID men att detta skydd snabbt försvinner och faller till en lägre nivå än före boostern. Artikeln extrapolerar trenderna in i framtiden (detta är alltid riskabelt) och varnar för att vaccinernas effekt på kort sikt kan börja ses som förvärvat immunbristsymptom. Vad är då förvärvat immunbristsyndrom i lite bättre kända termer? På engelska talar man om Acquired Immune Deficiency Syncrome d.v.s. AIDS vilket antagligen är lättare att placera in på kartan … notera att jag inte med detta påstår att det skulle vara fråga om samma sak!
År 2017 hade vi ungefär 107 döda i cancer per 100 000 invånare i Finland. Notera döda inte cancersjuka (totalt strax under 6000 döda). Vi hör inga klagomål om att sjukvårdssystemet håller på att falla ihop trots att antalet döda i detta fall varje år är tio gånger högre än antalet dödsfall till följd av CORONA. Antalet människor som lever med cancer är likaså ca. tio gånger större än antalet COVID smittade i Finland och som känt är cancervård mycket resurskrävande.
Då vi följer World Economic Forum d.v.s. de superrikas planeringsorganisation så hör vi att CORONA-epidemin ger oss en fantastisk möjlighet till en världsomspännande omstart av samhället som bl.a. skulle innebära ett rättvisare samhälle, en hållbar värld etc. detta presenteras av representanterna för de rikaste av de rika. De fattiga och medelklassen skall beskattas via skatter på bl.a. fossila bränslen för att finansiera de superrikas elbilar /sark. Är de superrikas planer över huvudtaget trovärdiga så länge dessa utan problem flyger sina privata jetflygplan medan pöbeln förväntas låta bli att resa med flyg.
Dagens politiker har outsoursat sitt ansvar. Vem säger att man får rätt avvägda åtgärder då politikerna delegerar sitt ansvar till professionella medicinare? Det är självklart att medicinarna bör veta hur man skall hantera smittsamma sjukdomar och de rekommendationer som framförs utformas för att minimera smittspridning och på slutändan antalet insjuknade. Vad experterna, läkarna, inte är experter på är en avvägning av nyttan med åtgärderna vägda mot de skador utöver eventuell medicinsk nytta på människor och samhälle åtgärderna ger.
Nedstängning av samhället slår mycket hårt mot små och medelstora företag i kultur- och servicebranchen. Mängder av livsverk slås i spillror i namn av den farliga CORONA-epidemin. Förstörelsen kommer på slutändan att synas i form av ökade dödsfall i cancer och andra sjukdomar eftersom många patienter inte har vågat söka sig till vård eller för att vård inte har erbjudits då focus har legat på pandemin. En helt annan sak är att det kommer att vara väldigt intressant att se hur dödligheten i t.ex. cancer påverkades under coronaåren och tiden strax efter. Kommer man att kunna visa att dödligheten i cancer steg/sjönk/förblev oförändrad då resurser omfördelades till covid. I princip borde man på detta sätt kunna få en bild av cancerbehandlingens verkliga effekt.
Hur många människor kommer att göra självmord under de kommande åren till följd av en samhällelig destruktion som dessa individer har varit fullständigt oskylldiga till? Notera att antalet självmord idag ligger på en nivå som är nästan två gånger större än antalet COVID-döda. Borde vi inte fokusera på självmord om antalet döda är avgörande? Speciellt för självmord är också att de tenderar att slå mot unga och medelålders människor med livet framför sig … inte mot åldringar som redan passerat ”bäst före datumet”.
Vi kan idag (11.1.2022) klart se att vaccinen inte har någon positiv effekt på smittospridningen. Det finns klara forskningsrön som tyder på att vaccinerade proportionell smittas något mer än ovaccinerade. Detta är intressant då argumentet då de experimentella vaccinen lanserades var att vaccination skulle stoppa spridningen av Covid. Nu lyder argumentet att även fullt vaccinerade kan bli smittade men att risken att bli svårt sjuk är mindre. Om vaccinen inte har effekt på smittospridningen och erfarenheterna från bl.a. Storbrittanien visar att sjukhusen fylls också av vaccinerade så frågar man sig varför man fortsätter att försöka tvinga ovilliga att vaccinera sig.
Nature Medicine publicerade 14.12.2021 en artikel som tydligt visar att risken för myocarditis d.v.s. hjärtmuskelinflammation är större hos personer vaccinerade mot Covid än hos personer som genomlidit Covid. Ett argument för vaccination har varit själva sjukdomen har utgjort en större risk än vaccinet. Detta verkar inte vara fallet för åldersklasserna under 40 år. Riskerna verkar öka ju lägre ner i åldrarna man går.
En forskningsrapport från Hong Kong tyder på att ca. en av 5400 vaccinerade drabbas av hjärtmuskelinflammation eller hjärtsäcksinflammation. Notera att Robert Malone uppskattar att incidensen är högre än min uppskattning. Rapporten konstaterar att fallen inte i allmänhet har varit allvarliga. Det finns tom. risk för död om en person med dessa problem tex. deltar i hård idrott något vi idag sannolikt ser hos vaccinerade toppidrottare.
Resultatet av de drakoniska nedstängningarna är en samhällsförstörelse utan like sedan det andra världskriget som samtidigt skuldsätter kommande generationer och bakbinder de nationella beslutsfattarna för årtionen framåt … detta är ur elitens synvinkel önskvärt och väl beskrivet i den globalistiska agendan. En djupt skuldsatt är aldrig fri något vi kan se i t.ex. Grekland men också Italien och Spanien. En djupt skuldsatt person eller stat kan via utpressning tvingas till nästan vad som helst och detta är det perfekta redskap den superrika eliten kan använda som murbräcka mot idag självbestämmande stater.
Vilket är argumentet för att blockera experter med fel åsikt från de stora internet plattformerna. Det vi behöver framom allt annat är en på fakta baserad diskussion som ger medborgarna möjlighet att ta egna beslut baserade på fakta. Det är sedan individens sak att ta beslut som senare med facit på hand kan visa sig vara rätt eller fel. Vilket är argumentet för att undertrycka avvikande åsikter. Nedanstående video diskuterar en tänkbar orsak.