Jag har lekt med en Clockwork PicoCalc som man kan köpa som en enkel byggsats. PicoCalc är egentligen ett tangentbord och en skärm med 320×320 pixlar d.v.s. en skärm som motsvarar en typisk hemdator från 1980-talets början t.ex. en Commodore 64. Byggsatsen görs till en fungerande dator genom att lägga till något av processorkorten Rasapberry Pi Pico, Pico2 eller Pico W. Hobbyister har också kört andra processorer och lyckats köra Linux utan större problem. Användning av andra processorer än Pico kräver dock i allmänhet att man hackar hårdvaran d.v.s. löder om själva PicoCalc. Jag tycker av princip illa om att gå in och löda i fungerande hårdvara vilket är orsaken till att jag kör en normal PicoCalc och inte Linux.
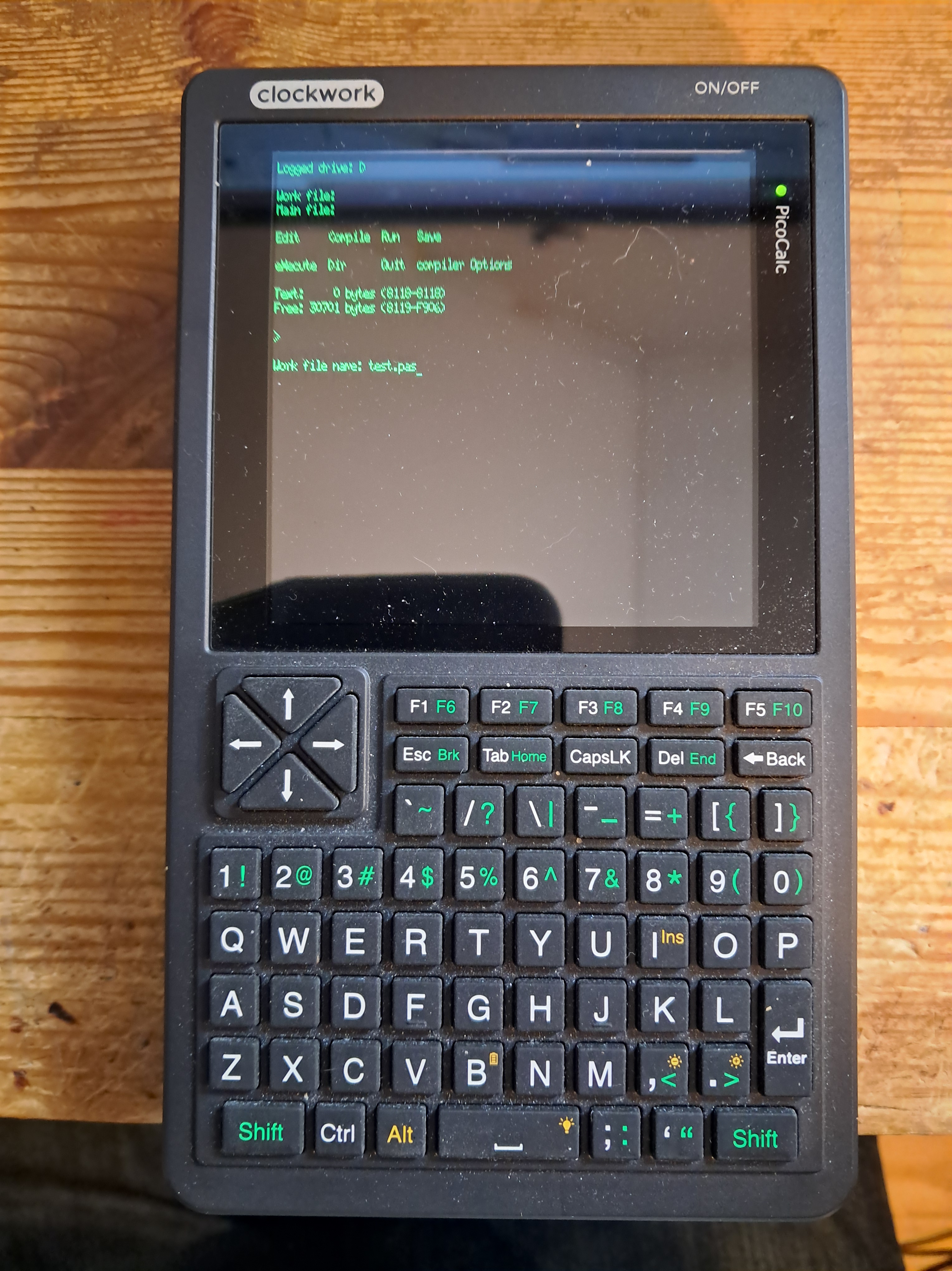
Bilden visar att Turbo pascal d.v.s. turbo har startat och programmet frågar efter den fil vi vill editera och kompilera. I vårt fall TEST.PAS. Vi ser en CP/M mikroskärm med radlängden 40 tecken. En speciell font har skapats för att få möjligast mycket text att rymmas på en rad.
PicoCalc ser ut som en normalstor kalkylator från 1980-talet i vilken man kan programmera och köra Basic, Python och Lua. Under Basic och Python fungerar den förvånande bra som en programmerbar kalkylator. Det visade sig snabbt att processorn är tillräckligt snabb och det finns tillräckligt minne för att köra operativsystemet CP/M som var dominerande från mitten av 1970-talet till mitten av 1980-talet. CP/M trängdes ut av IBM:s PC kring mitten av 1980-talet. IBM PC körde ett mycket liknande operativsystemsom CP/M kallat Ms-DOS.
https://en.wikipedia.org/wiki/IBM_Personal_Computer
https://en.wikipedia.org/wiki/CP/M
ARM processorn i en RPi Pico klarar av att emulera en Intel 8080 eller en Zilog Z80 i realtid. Pico:ns lilla minne räcker till för att ge CP/M ett fullt arbetsminne trots att en stor del av Pico kapaciteten går åt till att emulera en främmande processor.

Storleken på en Raspberry Pi Pico är ungefär två normalstora frimärken i bredd. Bildens Pico har storleken 20×50 mm.
Ett mycket vanligt programmeringsspråk på 1980-talet både under CP/M och PC-DOS var Turbo Pascal som erbjöd en enligt dåtida mått mycket trevlig programmeringsomgivning för programspråket Pascal. Pascal är ett i många avseenden mycket klarare och ”renare” programspråk än t.ex. programspråket C som användes då Unix och senare Linux skapades. Med hjälp av Turbo Pascal kunde man i akademiska sammanhang enkelt t.ex. göra statistiska analyser på en liten bordsmaskin, analyser som tidigare krävde tillgång till en stordator med all den byrokrati och kostnad detta medförde. Med hjälp av Turbo Pascal kunde man också med hjälp av diverse instickskort använda en PC för förvånande avancerade automatiska mätningar. Turbo Pascal fanns tillgängligt både för CP/M baserade datorer och för Ms-DOS maskiner d.v.s. IBM-PC samt mängder av liknande kloner.
Att köra program i 64 kilo Byte minne
Dagens datorer t.ex. en PC tenderar att ha ett centralminne på 4-32 GigaByte ibland mera. Min personliga PC som kör Linux har 32 GigaByte minne som är 500 000 gånger större än än det totala minnet i forntidens CP/M dator.
Jag kompilerade på skoj ett program TEST.PAS som ger ett nytt kommando till CP/M systemet som enligt Unix tradition kallas cat d.v.s. catenate eller skriv ut/kombinera ihop. Programmet kan läsa en eller flera textfiler och skriva ut dem till skärmen eller skicka resultatet till en annan fil. Under Linux skulle jag kunna skicka filen utan förändringar till t.ex. LPR dvs skriva ut till skrivare allt det som annars skulle gå till skärmen. Jag antar att jag inte kommer riktigt så enkelt undan under CP/M. Länken nedan diskuterar hur man kommer åt en skrivare, stans för hålremsa etc. under CP/M.
Då jag kompilerar programmet under Turbo Pascal under CP/M på PicoCalc får jag ett körbart program med storleken 635 bytes vilket motsvarar en vanlig text utskriven med 80 tecken par rad som då blir ungefär åtta rader lång. Jag testade programmet under CP/M så att jag använde det kompilerade programmet till att lista ut sig själv på PicoCalc skärmen. Texten är väldigt liten och ganska svårläst men programmet fungerade OK.
En intressant fråga blir då: Om jag tar samma program och kompilerar det under Linux (eller Windows eller Mac) hur stort blir då programmet på en modern dator? Notera att jag kompilerar för användning på kommandoraden helt utan GUI (grafiskt användargränssnitt). Om jag skulle skapa ett GUI för programmet gissar jag att det skulle växa ytterligare med kanske en faktor tio.
För kompileringen under Linux använde jag fpc d.v.s. Free Pascal Compiler som är basen i bl.a. Lazarus som idag är en trevlig omgivning för att generera program med grafiskt användargränssnitt GUI. Lazarus är mycket nära besläktad med Delphi (tidigare Borland Delphi). Lazarus är trevligt eftersom program enkelt kan skrivas för Linux, Windows, Mac, Android och FreeBSD och det finns funktionalitet som i hög grad förenklar designen av ett program med GUI. Fpc är således funktionsmässigt nära släkt med Borlands Pascal d.v.s. Turbo Pascal.
Jag kompilerade om programmet TEST.PAS under fpc med:
fpc -gl TEST.PAS
Kompileringen gick igenom utan problem men jag putsade bort en del onödiga fyllnadstecken i slutet av filen, tecken som i sig inte störde kompileringen. Då jag körde programmet:
./TEST TEST.PAS
Skrevs texten till TEST.PAS ut korrekt men jag fick ett felmeddelande på den nästsista raden (se programlistningen nedan) där programmet försöker stänga filen wrf d.v.s. en fil som används om man skulle vilja att resultatet går till en annan fil och inte på skärmen. Om jag skriver till skärmen behövs inte wrf och om jag försöker stänga wrf som aldrig har öppnats uppstår det ett fel. Felet är enkelt att åtgärda genom att kontrollera om vi har alternativet redirect innan vi försöker stänga filen. Längden på det körbara programmet blev nu under 64-bitars linux med kompilatorswitchen -gl som jag använde för att komma åt vilken rad i programmet som gav felet 420968 Byte d.v.s. ungefär 663 gånger större än under CP/M.
Om jag kompilerar om programmet efter rättning utan flaggan -gl blir resultatet 188304 Byte d.v.s. ungeför 297 ggr större än under CP/M.
Vad beror storleksskillnaderna på? En självklar orsak är naturligtvis att datorns s.k. ordlängd d.v.s. hur lång en typisk instruktion är har vuxit från 8-bitar till 64-bitar. Om vi antar att vårt program fortfarande behöver ungefär samma maskinspråksinstruktioner så kan vi få en vettigare jämförelse genom att dividera Linux-varianten med åtta d.v.s. ungefär 23538 instruktioner vilket är 37 ggr större än antalet instruktioner i CP/M varianten. Jag gissar att man genom väl genomtänkta optimeringar vid kompileringen kan krympa Linuxvarianten ytterligare. En stor orsak till att programmet har blivit större är antagligen kontroll av olika fel d.v.s. debuggning som utvecklats mycket under åren. De bibliotek vi länkar mot under Linux har bättre funktionalitet men de har också vuxit betydligt och innehåller sannolikt kod vi inte behöver. Vid kompileringen kan vi ange olika nivåer av optimering som påverkar snabbhet , minnesåtgång samt stöd för olika typer av felsökning. Körning av programmet ger:
./TEST TEST.PAS
ParamCnt=1/home/lasi/Prog/Pascal/TEST
Testing for file redirection
Got last par=TEST.PAS
TEST.PAS
program cat(input,output);
(* Make a new CP/M command cat
cat xxx yyy zzz … List all files to screen
cat xxx yyy >zzz List files xxx, yyy to the file zzz
*)
var i,nfiles:integer;
red:Boolean;
rdf: Text;
wrf: Text;
line: String[255];
destF: String[10];
function CkRedirect: boolean;
(* Is the destination a file or stdout?
The last file is assumed to be the redirection file if it exists.
Write all non redirection files to a temporary file and then
dump that to stdout or rename it to the destination file.
*)
var line:String[80];
begin
writeln('Testing for file redirection');
line := ParamStr(ParamCount);
writeln('Got last par=',line);
if (line[1] = '>') then
begin
writeln('Found redirect');
CkRedirect := True;
end;
end;
begin
writeln('ParamCnt=',ParamCount,ParamStr(0));
nfiles := ParamCount;
red := False;
if CkRedirect then
begin
writeln('Redirect');
nfiles := ParamCount - 1;
red := True;
destF := ParamStr(ParamCount);
Delete(destF,1,1); (* Remove '>') ) writeln('Redirect to:', destF); end; for i:=1 to nfiles do begin ( Type one file ) writeln(ParamStr(i)); Assign(rdf,ParamStr(i)); Reset(rdf); if red=True then begin Assign(wrf,destF); Rewrite(wrf); end; while not Eof(rdf) do begin Readln(rdf,line); if red=True then begin Write(wrf,line); end else Writeln(line); end; close(rdf); Writeln(' '); end; ( Caused error on the fpc compiler *)
if CkRedirect then close(wrf);
Writeln('Done …');
end.
Testing for file redirection
Got last par=TEST.PAS
Done …
Konklusion
Den här lilla programmeringsövningen visar egentligen hur ofattbart mycket tekniken har utvecklats under en livstid. Generellt kan man antagligen säga att alla intressanta parametrar har förbättrats med en faktor tusen eller mera. Några exempel:
- Processons klockfrekvens 1 MHz –> 4 GHz (dagen datorer är ungefär 4000 ggr snabbare sett till processorns klockfrekvens.
- Maskinens centralminne RAM 64 kByte –> 64 GByte (1 000 000 gånger större minne i dagens persondatorer av topp klass).
- Skivminne/Lagringsminne 100 kByte –> 4 TByte (4 000 000 ggr större idag).
- Maskinens pris $5000 –> $100 (50 ggr dyrare än idag). Notera att jämförelsen är felaktig eftersom penningvärdet har försämrats kraftigt på 40 år. Jag gissar att en korrekt jämförelse kunde vara åtminstone 100 ggr.
Om vi glömmer dagens AI boom där AI av vanliga användare körs över nätet och således inte belastrar den egna maskinen i någon större utsträckning så används datorerna fortfarande till liknande uppgifter som i ”forntiden” d.v.s. textbehandling, skicka brev och hantera kalkylark av olika typer. Gårdagens datorer kändes responsmässigt ungefär lika som dagens datorer. Vart har en prestandaökning på mellan 1000 och 1 000 000 ggr. försvunnit? Min uppfattning är att vi har fått en ofantlig mängd ”bling” som egentligen endast gör skärmen trevligare att titta på. Vi har halvtransparenta fönster som uppdateras hela tiden medan vi flyttar dem. En gammal dator skulle ha storknat genast. I våra datorer körs mängder av program i bakgrunden hela tiden. Program som meddelar oss att vi har fått meddelanden, program som skickar information om var vi gör till Microsoft etc. Det är lätt att bränna datorkapacitet och minneskapacitet i en värld där maskinen jag använder egentligen redan länge har varit tillräckligt kraftfull för det den skapades för.
Min laptop som också kör Linux fungerar helt OK trots att den är strax över tio år gammal. En bekant fick problem d.v.s. den heliga röken som datorn antagligen kör på slapp ut och maskinen slutade fungera. Jag hjälpte personen att rädda foton och dokument från datorn och fick sedan överta skrotet. Efter egen reparation har maskinen fungerat klanderfritt i många år. Jag kör en linuxvariant där allt onödigt ”bling” är bortplockat och maskinen fungerar bra som den är.
Ett annat intressant exempel på datorns ofantliga utveckling är ”mini”-datorn PDP-11 som operativsystemet Unix utvecklades på. Maskinen skulle ha kostat en privatperson tiotals tusen dollar att köpa. Jag har idag en replica av en PDP-11/70 d.v.s. den sista PDP:n som hade en frontpanel som tillåter mig att knappa in maskinkod bit för bit. Min replika kör, liksom CP/M på PicoCalc, en emulator men i detta fall på en Raspberry Pi 4. Den emulerade minidatorn från 1970-talet kör engefär tio gånger snabbare än orginalet trots att varje maskininstruktion emuleras av ett emulatorprogram på Raspberry Pi. En raspberry pi kostar idag beroende på variant kring 100 Euro.
Världens första egentliga superdator var Cray-1. Maskinen användes för mängder av vetenskapliga beräkningar. Man har uppskattat att en Raspberry Pi 5 (100 Euro), då man använder display hårdvaran (GPU) som en vektorprocessor är snabbare än en Cray-1 superdator. En Cray-1 behövde ungefär 115 kW eleffekt. En Raspberry Pi behöver ungefär 7W. Även på effektområdet ser vi alltså en förbättring på ungefär sextontusen gånger.