I Finland kännetecknas Juli månad ofta av att morgontidningen är extremt tunn. Många journalister är lediga och olika inhoppare försöker fylla det uppkomna tomrummet. Jag reagerade på två ledare i den finlandssvenska ”huvudtidningen” Hufvudstadsbladet (Hbl) skrivna av Peter Buchert. Den första ledaren ingick i Hbl den 14.7 och den andra följande dag d.v.s. den 15.7.
Peter Buchert är tydligt väldigt intresserad av natur och miljö men samtidigt en person som jag i många år har uppfattat som en aktivist som kallar sig journalist. Aktivistjournalister verkar idag uppfatta sig inte som rapportörer och förmedlare av information utan som influencers … något jag har sett i skrift i samma tidning Hbl där någon av tidningens journalister filosoferade över sitt uppdrag. Jag sparade beklagligtvis inte ifrågavarande artikel.
En influencer vinklar allt, det må vara olyckor, väder eller något annat så att rapporteringen skall stöda den underliggande agendan.
Jag skrev en insändare gällande den första ledaren som jag skickade till Hbl. Jag väntade mig inte att den skulle tas in. Idag två veckor senare börjar rötmånaden gå mot sitt slut och det verkar självklart att Hbl inte publicerar min kommentar varför jag tar mig friheten att använda min egen text nedan.
Peter Bucherts rötmånadsskrönor #1
Peter Buchert ledare i Hbl den 14 är ett intressant exempel på hur en aktivist ser på världen. I ledaren reagerade jag på ett intressant påstående som jag gärna skulle få en förklaring på: “På senare år har klimatförändringarna försvårat möjligheterna att spela VM fotboll. VM i Quatar 2022 flyttades till hösten för att det över huvudtaget skulle gå att spela.”
En enkel sökning gällande de normala temperaturerna i Quatar ger svaret “Den heta perioden maj till oktober bör undvikas. Juli uppfattas som den varmaste månaden med temperaturer på 32 till 43 Co även om det inte är ovanligt att temperaturen ibland kan gå upp till 50 Co i juli och ibland i augusti”.
Min enkla fråga till Peter Buchert är varför lade han till påståendet att “klimatförändringarna” gjorde det omöjligt att spela fotboll i Quatar på sommaren? Klimatet i Quatar, som gränsar till stora ökenområden, är helt enkelt sådant att det inte är lämpligt att spela fotboll där under den hetaste perioden på sommaren, detta faktum har ingenting att göra med eventuella klimatförändringar.
Om en lögn upprepas tillräckligt många gånger tenderar den att uppfattas som en sanning.
Lars Silen fysiker Esbo
Hur ser en normal sommar ut i Quatar? Vår vän AI konstaterar:
Ordinary summer temperatures in Qatar are sweltering and dry, with daily highs averaging around 40°C to 41°C (104°F–106°F) and peaks often exceeding 45°C (113°F).
Summer Temperature Breakdowns (June – September)
- Average Daytime Highs: 40°C to 41°C (104°F to 106°F), with July and August recording the hottest averages.
- Average Nighttime Lows: 31°C to 32°C (88°F to 90°F).
- Extreme Highs: Extreme heat waves can push temperatures past 50°C (122°F).
Humidity and Climate Factors
- Muggy Coastal Air: High humidity from the Arabian Gulf makes coastal areas like Doha feel much hotter during the second half of summer.
- Rainfall: Summer months experience virtually 0 mm of rainfall.
Jag upprepar den sista meningen i min icke godkända insändare med ett litet tillägg:
Om en lögn upprepas tillräckligt många gånger tenderar den att uppfattas som en sanning vilket naturligtvis är orsaken till att en aktivist gör detta.
En intressant fråga värd att ställa är naturligtvis hur dödsfall förorsakade av naturkatastrofer, ”klimatförändringar” och annat kopplat till detta har utvecklats (Källa: International Disaster Database) under de senaste hundra åren. Om man lyssnar på, våra inte speciellt väl pålästa media, kunde man få intrycket av att vi är på väg mot en aldrig tidigare skådad katastrof vilket emotionellt ”bevisas” av otaliga bilder av skogsbränder, orkaner och uttorkade fält. Modern teknik gör att bilder från alla ”rafflande” naturfenomen finns tillgängliga både som bilder och i form av video. Bilden nedan visar vad som sker i verkligheten.
Media har implementerat modellen i boken ”Orwell 1984” där vitt har blivit svart och sanning har blivit lögn. Alla media sjunger samma falska visa som tas från ett mycket litet antal globala nyhetskällor:
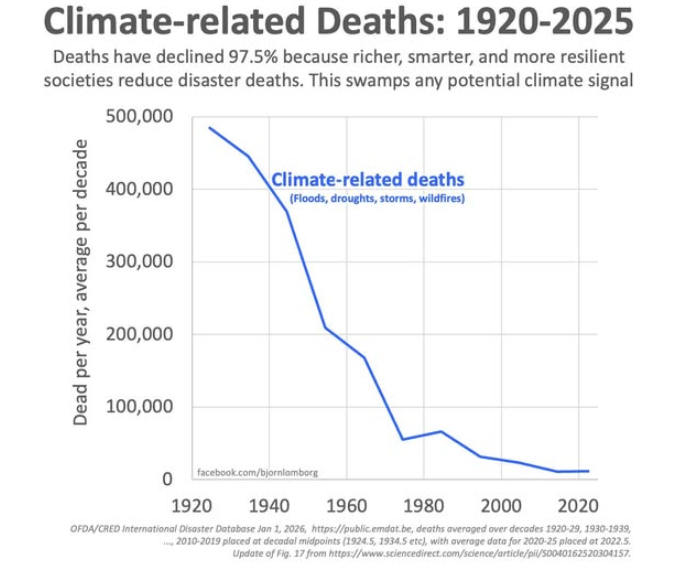
Som bilden visar har chansen att dö till följd av olika naturkatastrofer gått ner till en liten bråkdel av situationen för hundra år sedan. Orsaken till den otroliga positiva utvecklingen är naturligtvis att möjligheterna att skydda sig förbättras med en ökande global levnadsstandard och med ny teknik som gör att befolkningen i ett utsatt område kan varnas på förhand.
Följande skröna publicerades följande dag
Peter Bucherts rötmånadsskrönor #2
I Peter Bucherts ledare den 15.7 refererar han till “I dag är 300 miljoner människor akut hungriga. Det betyder att de inte vet hur de skall skaffa följande måltid. Siffran är tre gånger så stor som för fem år sedan.”
En aktivist lägger fram data, helst stora tal, utan koppling till vad som har skett. Hungersnöd och undernäring är främst kopplade till krig och interna samhälleliga konflikter inte “klimatförändringar”. Det är klart att naturkatastrofer spelar en roll men den främsta orsaken till att dödstalen till följd av naturkatastrofer har minskat till en bråkdel under de senaste hundra åren är att levnadsstandarden globalt stigit kraftigt. Högre levnadsstandard tillåter säkrare hus, bättre räddningstjänst samt varningar på förhand då man vet att en orkan eller något annat riskabelt är på väg.
Under perioden 1990 till 2019 minskade antalet barn med kronisk undernäring globalt från ungefär 38% år 1990 till 7.9% år 2019 d.v.s. 2019 var undernäring ungefär en fjärdedel av situationen 1990. Förbättringen var ofattbart stor i positiv riktning.
Ledaren innehåller även kommentaren att mängden undernärda idag är 300 miljoner vilket är tre gånger fler än för fem år sedan. Då man kollar med WHO, UNICEF och Our World in data så ser man får man lite proportion på problemet:
År 2022 var ungefär 390 miljoner människor underviktiga (WHO) medan 2500 miljoner var överviktiga inklusive 890 miljoner som var feta. Undernäring är ett problem vi måste eliminera men det stora problemet idag är fetma och alla de sjukdomar fetma för med sig med en fördröjning på 20-30 år såsom fettlever, typ 2 diabetes och cancer.
Lars Silen fysiker Esbo
Jag skickade inte in kommentar nummer två eftersom jag såg det som meningslöst.
Vi får ideligen höra hur ”klimatförändringarna” kommer att skapa problem i matproduktionen och då naturligtvis i förlängningen skapa hungersnöd. I verkligheten är inte hunger idag det stora problemet utan tillgången till nästan obegränsade mängder mat som egentligen inte borde ätas av människor. Resultatet är en världsomfattande epidemi av fettma, typ2 diabetes, icke alkohoinducerad fettlever och på slutändan cancer. Bilden nedan visar trenden i produktionen av spannmål. Idag är orsaken till svält inte bristen på mat utan politiska oroligheter som gör att det inte går att lokalt producera mat effektivt samt att det inte går att transportera mat till områden där maten behövs (Källa: Bjørn Lomborg).
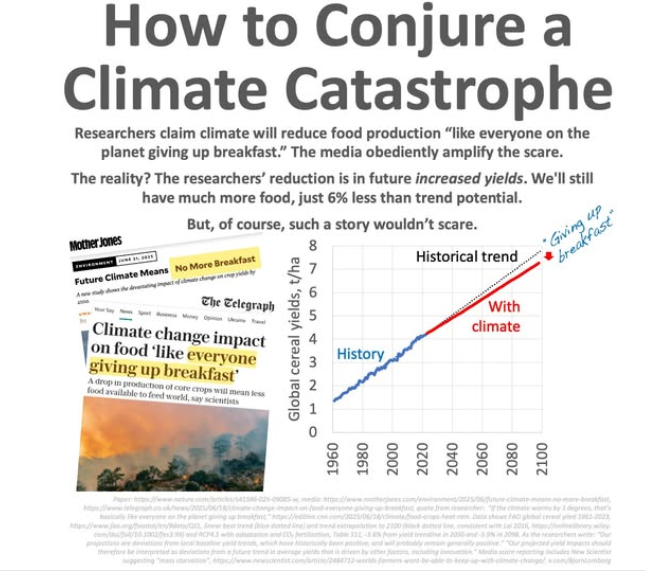
Media fokuserar idag på bränder i Europa, bränder som till 90% är förorsakade av människan genom slarv eller anlagda av pyromaner. De naturliga orsakerna d.v.s. 10% har inte signifikant ändrats. Jag skrev ingen ytterligare rötmånadskommentar gällande rapporteringen av bränder i Europa. Notera att det är ytterst beklagligt att bränder sker och människor och egendom kommer till skada.
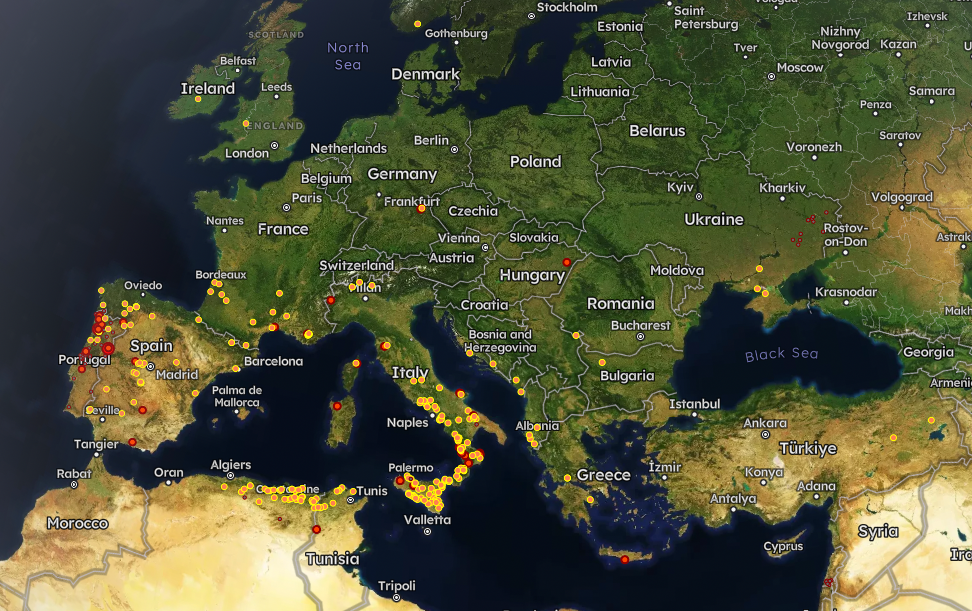
Hur ser situationen ut idag i förhållande till en normal sommar?
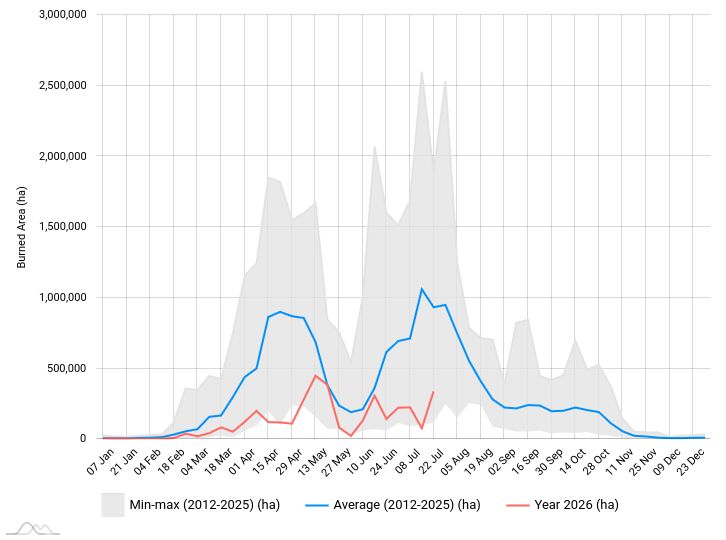
Som känt är det varmt i sydeuropa på sommaren helt oberoende av ”klimatförändringarna”. Då det blir varmt mot sommaren i sydeuropa blir naturen brun och torr och samtidigt går pratet om en katastrofal uppvärmning upp i falcett och genom att alla media citerar samma bränder dag efter dag skapar man en bild av en katastrof. Grafen ovan visar situationen i hela Europa år 2026 (röd graf) jämfört med ett normalt år (blått) som i sin tur ligger långt från ett år då det brunnit katastrofalt. Det är klart att situationen innan sommaren tar slut kan ändras. Notera hur rapporteringen som främst gäller Spanien och Frankrike, eftersom där råkar vara något varmare än normalt, pekar på bränderna som aldrig tidigare skådade. Om vi ser på bränder över hela Europa så ser man att Europa år 2026 är ett år med få bränder men detta är inte vad media säger (Källa: https://gwis.jrc.ec.europa.eu/apps/gwis.statistics/seasonaltrend).
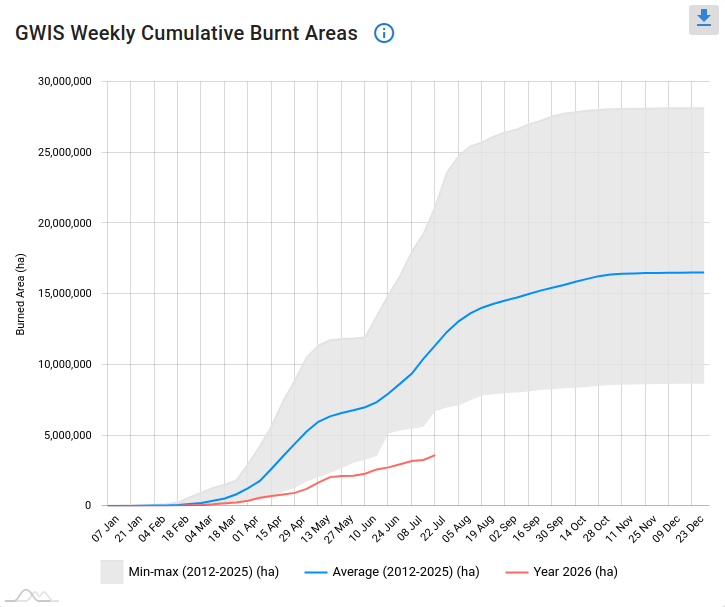
Bilden nedan visar brandsituationen i Europa baserad på satellitobservationer. Det är intressant att notera hur lite det har rapporterats om bränder i Italien där det inte råkar vara riktigt lika hett men där naturen, som alltid på sommaren, är torr och eldfängd.