Området mellan Esbo Å:s och Gumböle Å:s utlopp används under sommaren som betesmark för kor. Under höst och vinter finns korna på annat håll och de stora öppna området fungerar bra för flygning med drönare. I den här videon flyger jag en rätt stor Yuneec Q500 drönare. Min goda vän Anders flyger en Dji Phantom 3 Professional. Kameratekniken i de båda drönarna är väldigt lika och det är främst en smakfråga vilkendera drönaren som producerar en bättre video. Dji Phantom 3 är eventuellt lite piggare att flyga … om detta är en fördel eller nackdel kan man fråga sig.
Video: Området mellan Esboå och Gumböleå nära åarnas utlopp kallas Glasdalen.
Nya regler för flygning med drönare kräver att drönaren är registrerad och att operatorn har avlagt ett prov på nätet. En stor drönare, båda drönarna på videon väger betydligt över ett kilogram, får inte flygas över utomstående och man måste hålla tillräckligt avstånd till hus och industri. Videons område är väl lämpat för drönarflygning men man måste medvetet undvika att flyga för nära småhusen i riktning nord ost.
Bilden visar en satellitbild av Glasdalen mellan de två åarna. Småhusområdet söder om Kristallvägen bör man vara medveten om för att inte gå för nära. Skogsområdet i väster är naturskyddsområde.
Jag har två drontyper som jag regelbundet flyger med. DJI:s Phantom samt Yuneec Typhoon. Dronerna är rätt likvärdiga ur flygsynvinkel och kamerornas kvalitet är mycket lika. Det finns dock en betydande skillnad mellan dronfamiljerna.
Dji använder intelligenta batterier d.v.s. laddningslogiken finns i själva batteriet. Batteriet kan alltså helt autonomt följa med sin egen användning vilket är viktigt då man använder moderna LitiumPolymer (LiPo) batterier. Ett LiPo batteri tycker inte om att vara tomt men det skadas också på sikt av att vara fulladdat. Egenskaperna hos ett felbehandlat batteri förändras bl.a. så att batteriets inre motstånd stiger vilket ur dronens synvinkel syns som höjd batteritemperatur under flygningen och kortare flygtid. Dji:s batterier laddar själja ur sig till ca. 60% laddningsnivå inom några dagar om batteriet inte används efter laddning.
Yuneecs batterier är inte intelligenta d.v.s. hela underhållsansvaret faller på användaren. Det är på mitt asnsvar att se till att batterier då de lagras har en laddningsgrad kring 60% för att livslängden skall bli så lång som möjligt. Ett hjälpmedel som jag har för detta ändamål är en intelligent laddare (inte Yuneecs laddare) som har olika program för laddning, urladdning och underhållsladdning. Det jag har saknat är ett enkelt sätt att mäta batteriernas inre motstånd och det är detta denna artikel kommer att handla om.
Då ett batteri belastas kommer det att ske ett inre spänningsfall i batteriet d.v.s. den spänning man ser över batteriets poler kommer att sjunka vilket betyder att t.e.x. en drons varningssystem för låg batterispänning slår på allt tidigare ju högre det inre motståndet blir. Om dronen vid flygning behöver t.e.x. 2A ström kommer ett inre motstånd på 70 milliohm att sänka batteriets spänning med 0,14 V vilket motsvarar flera minuters flygning.
När skall jag kasta ett batteri
Ett batteri är slut då flygtiden blir för kort samt då batteriet eventuellt börja uppföra sig konstigt d.v.s. det kan efter någon minuts flygning ge en batterivarning som tvingar fram en plötslig påtvingad landning för att undvika krasch. Ett sätt att se när ett batteri börjar nå slutet av sitt liv är att mäta det inre motståndet samt naturligtvis ibland mäta den effektiva flygtiden med ett batteri.
Mätning av det inre motståndet
Bilden visar, i form av ett kretsschema, ett batteri som belastas över ett motstånd. För att kunna beräkna det inre motståndet måste vi mäta batteriets spänning obelastat (i vila) samt spänningen då batteriet är belastat. Vi vill också undvika lång urladdning innan vi mäter det belastade batteriets spänning eftersom belastningen också medför att spänningen sjunker till följd av att batteriet laddas ur.
Mätning av batteriets spänning med voltmätaren (V) obelastat då switchen är öppen och belastat då batteriet urladdas genom lastmotståndet Rl.
Då batteriet är obelastat så går det nästan ingen ström genom batteriet, endast en mycket liten läckström går genom voltmätaren kanske 1 uA. Detta betyder att den spänning voltmätaren mäter är batteriets spänning eftersom spänningsfallet över Ri är ungefär lika med noll.
Då man sluter switchen SW kommer batteriet att laddas ur med en ström som beroende av batterityp är mellan 1 och 1.5 A. Batteriets inre motstånd kommer då att leda till ett spänningsfall inne i batteriet med storleken strömmen*inre_motståndet eller Ui=I*Ri . I prktiken kan man se detta så att spänningen sjunker då batteriet laddas ur.
Då batteriet är obelastat är den mätta spänningen:
Vb = det obelastade batteriets polspänning
Då batteriet belastas mäter vi en spänning:
(1) Vl = Vb – I*Ri
Där:
I = strömmen genom lastmotståndet som vi i mitt fall vet att det är 10 ohm
Rl = lastmotståndet 10 ohm
Ri = batteriets okända inre motstånd
Vb = det obelastade batteriets spänning.
Strömmen kan vi beräkna ur den mätta spänningen med last:
(2) I = Vl/Rl
Vi kan lösa Ri ur ekvation (1) och får då:
(3) Ri = (Vb-Vl)/I
Vi byter ut I ekvation (3) mot I taget ur (2) och får då:
(4) Ri = Rl * (Vb-Vl)/Vl
Vi ser alltså att vi helt änkelt gör två spänningsmätningar den första med obelastat batteri och den andra med ett belastat batteri och därefter lägger vi in värdet i (4) tillsammans med det kända vädet på Rl=10 ohm. Lätt som en plätt där inget kan gå fel eller hur?
En Arduino Uno är ett billigt litet mikroprocessorkort med en trevlig utvecklingsomgivning. Processorn har en AD-konverter (voltmätare) med upplösningen 10 bitar d.v.s. mätområdet 0 … 5V delas in i 1024 spänningssteg. Den enklaste mätaren kunde således byggas utgående från en Arduino Uno kopplad till ett 5V relä som styr mätning av obelastat respektive belastat batteri.
Jag skrev ett litet program som gjorde ovanstående mätningar med hjälp av Uno:s AD-konverter. Resultatet blev negativa värden på den inre resistansen. Hur kan jag få negativa värden på den inre resistansen? Då vi tittar på ekvation (4) så ser vi att spänningen med last då måste vara större än det obelastade batteriets polspänning! Hur är detta möjligt?
Uno:s AD-konverter tar sin referensspänning från processorkortets 5V matningsspänning. Ett relä drar rätt mycket ström d.v.s. när relät aktiveras d.v.s. SW är slutet kommer hela processorkortets spänning att sjunka till ca. 4,5V. Plötsligt blev referensspänningen 4,5 i stället för 5V och resultatet är att det ryms 1024 spänningssteg i 0…4,5V i stället för 0…5V d.v.s. steglängden minskar och då processorn mäter det belastade batteriets spänning tror den sig mäta en spänning som är större än det obelastade batteriets spänning.
Lösningen som samtidigt testar diagnosen var att mata relät med ett separat spänningsaggregat. Processorns spänning hålls bättre konstant och felen minskar radikalt.
Nu dyker följande problem upp. Mätningar av riktiga batterier tyder på att upplösningen d.v.s. den precision vi kan uppnå vid mätningen blir av storleksorningen 10 milliOhm vilket är nästan 25% av det inre motståndet i ett typiskt batteri. En enkel kontroll visar vad detta problem beror på.
Antag att inspänningen till AD-konvertern är något över halva maxspänningen t.ex. 3.5 volt vilket motsvarar ett mätvärde på 716 enheter av 1024. Antag nu att Vb och Vl skiljer med endast en enhet och att lastmotståndet är 10 ohm. Det minsta resistansvärdet vi då kan mäta får vi genom att beräkna:
Ri = 10*(716-715)/715 = 14 milliohm … inte bra!
Slutsatsen blev att mätaren måste få en bättre AD-konverter. Ett alternativ kunde ha varit att gå över till en ARM-baserad ”BluePill” processor som erbjuder en 12-bitars AD-konverter d.v.s. med samma uppställning som för Uno och omkompilering av programkoden kunde jag få fyra gånger bättre upplösning d.v.s. ungefär 3.5 milliOhm vilket är betydligt bättre. Ett annat alternativ hittade jag i miljonlådan i form av ett litet kretskort som jag nångång skaffade för ett annat projekt. Kretsen ADS1115 erbjuder en fyrkanalig 16-bitars AD-konverter som kontrolleras över en seriebus I2C. Genom att använda ADS1115 kunde jag fortsätta att använda Arduino Uno men mäta spänningar med god precision. Voltmätaren ADS1115 marknadsförs som 16-bitars men i praktiken är det en 15-bitars konverter då jag mäter positiva spänningar. 15 bitar ger 32768 spänningssteg d.v.s. 32 ggr bättre än Uno.
Mätprogrammet går på 60-rader vilket väl ryms i en Arduino Uno som erbjuder 32k minne för program (en Commodore 64 från ungefär 1980 hade ungefär den här kapaciteten). Programmet använder ett färdigt bibliotek för kontroll av ADS1115 vilket gör programmeringen mycket enklare …
// Name= resistance_ADS1115
// Lars Silen 2022
// This is free source code. Feel free to copy and modify.
#include "Arduino.h"
#include "ADS1115-Driver.h"
#define Rly 6
uint16_t V_battery;
uint16_t V_load;
float R;
float loadResistance=10.1;
ADS1115 ads1115 = ADS1115(ADS1115_I2C_ADDR_GND);
uint16_t readValue(uint8_t input) {
ads1115.setMultiplexer(input);
ads1115.startSingleConvertion();
delayMicroseconds(25); // The ADS1115 needs to wake up from sleep mode and usually it takes 25 uS to do that
while (ads1115.getOperationalStatus() == 0);
return ads1115.readConvertedValue();
}
void setup() {
Serial.begin(9600);
ads1115.reset();
ads1115.setDeviceMode(ADS1115_MODE_SINGLE);
ads1115.setDataRate(ADS1115_DR_250_SPS);
ads1115.setPga(ADS1115_PGA_6_144); // +/- 6.144 V
ads1115.setMultiplexer(ADS1115_MUX_AIN0_GND);
pinMode(Rly, OUTPUT);
}
void loop() {
Serial.println("Program to measure the internal resistance of 3s and 4s Yuneec LiPo batteries");
Serial.println("Ensure there is a very good contact to the battery.");
Serial.println("Keep your finger on the battery side connector!");
delay(1000);
digitalWrite(Rly,LOW); // Measure battery voltage
delay(100);
uint16_t V_battery = readValue(ADS1115_MUX_AIN0_GND);
Serial.print("V_battery: ");
Serial.println(V_battery);
Serial.println("Switch load to ON");
digitalWrite(Rly,HIGH); // Measure load voltage, switch load ON
delay(10);
uint16_t V_load = readValue(ADS1115_MUX_AIN0_GND);
digitalWrite(Rly,LOW);
Serial.print("V_load: ");
Serial.println(V_load);
R = (loadResistance*(V_battery-V_load)/V_load)*1000.0;
Serial.print("Internal resdistance milliohm:");
Serial.println(R,0);
Serial.println();
Serial.println();
delay(5000);
}
Det färdiga mätsystemet visas i bilden nedan. Den alternativa plattformen ”Blue Pill” är det lilla processorkortet som ligger på det silverfärgade lilla nätaggregatet som används för att driva reläet. ”Blue Pill” används inte utan finns endast med som illustration. Blue Pill är sannolikt 10 ggr kraftfullare än en Arduino Uno. Både en Uno och Blue Pill kostar sannolikt kring en tia. En Arduino Uno, Mega eller Due är dock mycket lättare att komma igång med eftersom de har skräddarsytts för Arduino utvecklingsomgivningen.
Den färdiga mätaren. Batteriet kopplas till de två banan-honkontakterna. Lastmotståndet är den guldfärgade komponenten. Motståndet är 10 ohm och effekttåligheten 50W.
Programmet körs från Arduino IDE så att utskrift sker till ”Serial monitor”. Det vore enkelt att ansluta en LCD-skärm på vilken resultatet kunde visas. Att lägga till en skärm och på detta sätt göra mätaren oberoende av en PC lämnas som övningsuppgift till läsaren!
Ett gammalt batteri har mätts. Det inre motståndet har närstan fördubblats jämfört med ett färskt batteri. Notera att batteriet har tre celler d.v.s. den inre resistansen är ungefär 24 milliOhm per cell. I ett färskt batteri är motsvarande värde ungefär 14 milliOhm per cell.
Pedofilön d.v.s. Jeffrey Epsteins paradisö erbjöd alla de perversioner någon kunde önska sig. Mängder av politiker och inflytelserika påverkare i samhället vallfärdade till pedofilön och var goda vänner med Epstein som under lång tid, konstigt nog ( /sark), verkade vara immun mot åtal. Det finns väl knappast någon som utgår från att Epstein erbjöd sina tjänster till samhällets toppskikt gratis? Att tillhandahålla unga flickor och pojkar till sexuellt nöje för samhällets toppskikt var som historien kunde utvisa farligt. Det är självklart att det sätt entrepenören kunde skydda sig själv var att dokumentera gästernas utsvävningar.
Utpressning är en enkel metod att tysta en kund men informationen om kunderna är i sig en extremt värdefull handelsvara. Utpressning blir ännu effektivare om offret kan fås att välja mellan att ta emot pengar eller att hängas ut i offentligheten. Mutorna som sådana blir med tiden nya hållhakar som ser till att offret förstår sin plats i ledet. Pengar och god press finns i överflöd för den som är användbar och följer order. Dagens melodi är: Gör som vi säger så får du pengar och synlighet och allt du kan önska dig, om inte så gör du kanske ”självmord” som Epstein.
Jacob Nordangård har en intressant artikel om dagens unga ledare däribland Finlands statsminister Sanna Marin, Frankrikes president Emmanuel Macron, Justin Trudeau i Canada och många fler. Dagens unga beslutsfattare har alla skolats genom World Economic Forum (WEF) som styrs av världens ekonomiska elit. Vilka är de metoder man använder för att få dessa unga ledare att gå i takt och att samtidigt upprepa samma mantra på nytt och på nytt? Notera att jag inte påstår att alla unga politiska ledare är köpta/styrda men det är förvånande ofta (/sark) man ser samma mall användas på nytt och på nytt globalt. Är orsaken att mallen är ett bra verktyg eller är orsaken att dessa skolade politiker borde uppfattas som skådespelarna i en dockteater där vi inte ser dem som håller i trådarna? Ett tänkbart svar finns i en intervju av Justin Trudeaus halvbror Kyle Kemper:
Kyle kemper konstaterar att Justin Trudeau inte följer sitt eget hjärta, utpressning är ett mycket effektivt verktyg.
”Han är Canadas regerings talesman och ledare, men de policyn och de initiativ han driver, som enligt min uppfattning är anti frihet och anti Kanada, kommer ner uppifrån från grupper som World Ekonomi Forum, Council on Foreign Relations och Bilderberg. De förstår behovet av att ha dess starka agenter inom regeringar och en sak vi har sett i regeringar i hela världen är svaga ledare som fungerar som talesmän.”(för eliten, min kommentar)
“Han följer inte sitt hjärta. Jag kan inte ärligt tro … det stämmer inte, det finns ingen verklig diskussion. Han får inte diskutera med Freedom Convoy (lastbilskaravanen i Kanada) och med dessa människor eftersom där finns mycket att packa upp/gräva i och mängder av allvarliga frågor.”
“När du ser på historien kring människor som Jeffrey Epstein och vilken deras roll var, att locka människor i en fälla och utpressa dem. Tänk på ett liv i överflöd och möjligheter, du kommer att göra misstag och bli tvingad att göra något illa.”
”Utpressning är ett effektivt verktyg.”
Jacob Nordangård har samlat en lista på unga ledare som har gått igenom WEF:s utbildning för unga ledare. Tror någon att världens miljardärer har gett dessa ledare utbildning endast för hjärtats godhets skull och att inga genkänster förväntas?
Listan som inte är fullständig har följande utseende:
More examples of influential Young Global Leaders [2]: Crown Princess Victoria of Sweden Crown Prince Haakon of Norway Crown Prince Fredrik of DenmarkPrince Jaime de Bourbon de Parme, Netherlands Princess Reema Bint Bandar Al-Saud, Ambassador for Saudi-Arabia in USA Jacinda Arden, Prime Minister, New Zeeland Alexander De Croo, Prime Minister, Belgium Emmanuel Macron, President, France Sanna Marin, Prime Minister, Finland Carlos Alvarado Quesada, President, Costa Rica Faisal Alibrahim, Minister of Economy and Planning, Saudi Arabia Shauna Aminath, Minister of Environment, Climate Change and Technology, Maldives Ida Auken, MP, former Minister of Environment, Denmark (author to the infamous article “Welcome To 2030: I Own Nothing, Have No Privacy And Life Has Never Been Better”) Annalena Baerbock, Minister of Foreign Affairs, Leader of Alliance 90/Die Grünen, Germany Kamissa Camara, Minister of the Digital Economy and Planning, Mali Ugyen Dorji, Minister of Domestic Affairs, Bhutan Chrystia Freeland, Deputy Prime Minister and Minister of Finance, Canada Martín Guzmán, Minister of Finance, Argentina Muhammad Hammad Azhar, Minister of Energy, Pakistan Paula Ingabire, Minister of Information and communications technology and Innovation, Rwanda Ronald Lamola, Minister of Justice and Correctional Services, South Africa Birgitta Ohlson, Minister for European Union Affairs 2010–2014, Sweden Mona Sahlin, Party Leader of the Social Democrats 2007–2011, Sweden Stav Shaffir, Leader of the Green Party, Israel Vera Daves de Sousa, Minister of Finance, Angola Leonardo Di Caprio, actor and Climate Activist Mattias Klum, photographer and Environmentalist Jack Ma, Founder of Alibaba Larry Page, Founder of Google Ricken Patel, Founder of Avaaz David de Rothschild, adventurer and Environmentalist Jimmy Wale, Founder of Wikipedia Jacob Wallenberg, Chairman of Investor Niklas Zennström, Founder of Skype Mark Zuckerberg, Founder of Facebook
Välkommen till vår sköna nya värld där svart kan göras till vitt, där krig kallas fred och där frihet kallas slaveri.
Personligen uppfattar jag att vi på sikt behöver en världsregering som kan hantera klart globala frågor men det världens elit jobbar för är en travesti på mina ideal. Som en finne skulle uttrycka det bildlikt: Man försöker klättra upp i trädet med rumpan före. Jag uppfattar att alla skyddsmekanismer som skulle kunna skydda oss från en tusenårig fascistisk diktatur saknas.
Länken ovan Välkommen till 2030 är värd att läsa. Mina tankar går till det forna Sovjetunionen som alltid var endast några år från riktig kommunism och utopia. Resultatet blev miljoner döda.
Vi har under 25-30 års tid sett en tilltagande infiltration av samhällets toppskikt med personer som jag uppfattar vara villiga att styras av världens multinationella storföretag och indirekt av deras ägare världens superrika oligarker. Hur denna infiltration har gjorts i detalj vet jag inte men det ligget nära till hands att samma metod som i början av artikeln beskrevs har använts i denna process. Tag reda på de potentiella ledarnas svagheter och se till att dessa svagheter utnyttjas och dokumenteras. En person som har att välja mellan rikedom och berömmelse eller att i skam bli uthängd i media har lätt att i små steg göra avkall på den egna moralen. Parallellt med WEF infiltration ser man en intressant trend där den traditionella vänstern plötsligt verkar stå på de rikastes sida, inte småfolkets. Som den cyniker jag har blivit så frågar man sig naturligtvis vad köpet av denna globala arbetarrörelse har kostat?
En korporatistisk rörelse där köpta politiker skapar en lagstiftning som passar de superrika samtidigt som politikerna själva rundligt belönas för sitt arbete och där lagstiftarna, se på situationen i Kanada, vägrar diskutera med sina väljare när det uppstår konflikter kan som jag uppfattar saken ses som mycket nära besläktad med 1930-talets fascism (det finns många definitioner). Samtidigt är det intressant att se hur tex. Trudeau anklagar motståndarna för att vara terrorister, rasister och nazister. Enligt handboken ”1984” blir svart till vitt och krig kallas fred. Då en modern WEF utbildad politiker gör ett uttalande/löfte kan det vara bra att alltid gå tillbaka till handboken och ställa frågan om ifrågavarande ledares handlingar bättre svarar mot motsatsen enligt modell från 1984.
Nedan en kort video där utvecklingsbiologerna, båda doktorer, diskuterar bl.a. situationen i Kanada och den inverterade bild media skapar.
I tidigare inlägg har jag visat hur man automatiskt kan översätta skriven text till morse och därefter generera en ljudfil som man t.ex. kunde köra igenom en radiosändare och om effekten är tillräckligt stark och reflexionerna i atmosfären optimala så kan man i princip höra morsemeddelandet överallt på jorden.
Vad gör jag om jag inte kan morse d.v.s. meddelandet är bara en okänd serie blippar. Kan jag skriva ett program som läser in morsekoden som ljud och översätter ljudmeddelandet till text? Det visar sig att detta, om signalen är optimal, är mycket enkelt att göra. Amplituden på alla ljudsignaler är exakt lika och alla pauser har någon av tre exakt definierade längder.
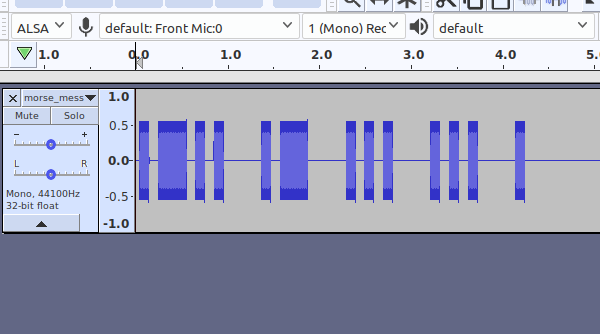
Signalen har följande utseende om jag tittar på ljudfilen med hjälp av programmet Audacity:
Vi ser att signalen är extremt ren och störningsfri. Pauser har ljudnivån noll helt utan något brus och signalen är en sinusvåg med konstant amplitud.
För att kunna läsa av signalen likriktar vi den först d.v.s. vi tar absolutvärdet av signalen så att alla negativa värden under strecket i figuren blir positiva. Signalen varierar våldsamt mellan 0 och ca. 0.5 och för att vi skall kunna bedöma om vi detekterar ljud eller tystnad filtrerar vi signalen så att vi beräknar medelvärdet av ett antal ljudvärden. Om medelvärdet är klart positivt så hör programmet ljud och då medelvärdet ligger mycket nära noll så är det tyst.
Programmet har en funktion/subrutin. Jag skrev denna gång programmet i språket python. Översättningen går till så att jag samlar ihop fragment av korta ljdsignaler (*) och långa ljudsignaler (-). Ljudsignalerna läggs till en textsträng ända tills vi stöter på en ”teckenpaus” d.v.s. en paus mellan bokstäver. Vi skickar nu textsträngen t.ex. ‘*-‘ till funktionen translate_char(tecken) som jämför morsetecknet med alla morsetecken i morsealfabetet och därefter skriver ut resultatet som bokstaven ‘a’ i detta fall. Vi nollar nu morsesträngen och börjar samla * rep – för följande tecken. För att läsa vad programmet gör så hoppar vi över funktionen translate_char och börjar läsa kommandoraden på vilken vi vill ha endast en parameter d.v.s. ljudfilens namn. Ljudfilen kan vara en mp3- eller en wav-fil. Om vi ger en mp3-fil så konverterar programmet automatiskt mp3 filen till en wav-fil eftersom wav-filen är lättare att hantera rent tekniskt.
#!/home/lasi/miniconda3/bin/python
# Name=morse_receiver.py
# The program reads an audio file and converts the audio back to plain text.
# The analysis works as follows:
# Read the message and record the lengths of sound and silence to a file.
# Determine the length of dots and dashes and the lengths of silence.
# Create a new file vith * - and the character interval + word interval.
# The file can now be analyzed for morse patterns and converted into text.
# This is free code. Use on your own risk.
import wavfile
import sys
import os
def translate_char(m_string):
m_string.strip()
if (m_string=="*-"):
return "A"
if (m_string=="-***"):
return "B"
if (m_string=="-*-*"):
return "C"
if (m_string=="-**"):
return "D"
if (m_string=="*"):
return "E"
if (m_string=="**-*"):
return "F"
if (m_string=="--*"):
return "G"
if (m_string=="****"):
return "H"
if (m_string=="**"):
return "I"
if (m_string=="*---"):
return "J"
if (m_string=="-*-"):
return "K"
if (m_string=="*-**"):
return "L"
if (m_string=="--"):
return "M"
if (m_string=="-*"):
return "N"
if (m_string=="---"):
return "O"
if (m_string=="*--*"):
return "P"
if (m_string=="--*-"):
return "Q"
if (m_string=="*-*"):
return "R"
if (m_string=="***"):
return "S"
if (m_string=="-"):
return "T"
if (m_string=="**-"):
return "U"
if (m_string=="***-"):
return "V"
if (m_string=="*--"):
return "W"
if (m_string=="-**-"):
return "X"
if (m_string=="-*--"):
return "Y"
if (m_string=="--**"):
return "Z"
if (m_string=="*--*-"):
return "Å"
if (m_string=="*-*-"):
return "Ä"
if (m_string=="---*"):
return "Ö"
if (m_string=="*----"):
return "1"
if (m_string=="**---"):
return "2"
if (m_string=="***--"):
return "3"
if (m_string=="****-"):
return "4"
if (m_string=="*****"):
return "5"
if (m_string=="-****"):
return "6"
if (m_string=="--***"):
return "7"
if (m_string=="---**"):
return "8"
if (m_string=="----*"):
return "9"
if (m_string=="-----"):
return "0"
# Primitive error check
print("Error m_string=",m_string)
print("Len=",len(m_string))
return "?"
if (len(sys.argv)<1) or (len(sys.argv)>=3):
print("Usage: morse_receiver.py snd_file")
exit(0)
# We only process wav-files. If I get a mp3 then convert it to wav
# Add further conversions here as nedessary.
# Filtypen bestäms utifrån filnamnet inte från magisk filtyp.
snd_file = sys.argv[1]
print("File to process: ",snd_file)
if snd_file.endswith('.mp3'):
print("MP3 file detected")
# Convert to a wav file
# model ffmpeg -i song.mp3 -ar 44100 song.wav
cmd = "ffmpeg -i "+snd_file+" -loglevel quiet -ar 44100 -y "+snd_file+".wav >/dev/null"
snd_file=snd_file+".wav"
print("Converted file="+snd_file)
# Convert the mp3 file to wav before processing.
os.system(cmd)
f = wavfile.open(snd_file, 'r')
frames=f.num_frames
wav_data=f.read_float(frames)
ampl=0
i=0
snd = False
nosnd = True
pstart=0
sstart=0
my_ch = "";
for d in wav_data:
ampl=(9*ampl+abs(d[0]))/10
i=i+1
if((ampl>0.1) and (nosnd==True)):
sstart=i
l = i-pstart
if(l<5000):
sp=0
elif((l>5000) and (l<20000)):
print(translate_char(my_ch)+" "+my_ch)
my_ch=""
else:
print(translate_char(my_ch)+" "+my_ch+"\n")
my_ch=""
snd = True
nosnd = False
elif((ampl<0.01) and (snd==True)):
pstart = i
if((i-sstart)<5000):
my_ch = my_ch + "*"
else:
my_ch = my_ch + "-"
snd=False
nosnd=True
Vi kontrollerar om vi fick en mp3-fil som parameter. Om detta är fallet så bygger vi upp ett kommando som en textsträng där programmet ffmpeg används för att göra en wav-kopia av mp3-filen. Kommandot utförs av det externa programmet ffmpeg genom att anropa det via system() d.v.s. vi gör inifrån programmet detsamma som vi skulle ha kunnat göra på kommandoraden.
if snd_file.endswith('.mp3'):
print("MP3 file detected")
# Convert to a wav file
# model ffmpeg -i song.mp3 -ar 44100 song.wav
cmd = "ffmpeg -i "+snd_file+" -loglevel quiet -ar 44100 -y "+snd_file+".wav >/dev/null"
snd_file=snd_file+".wav"
print("Converted file="+snd_file)
# Convert the mp3 file to wav before processing.
os.system(cmd)
Vi läser nu in hela ljudfilen i minnet, PDP11 skulle storkna i detta skede eftersom användarminnet skulle ta slut innan ens halva filen är läst … fint att ha lite mera minne i en modern dator! Vi skapar också några hjälpvariabler som vi behöver lite senare. Om jag skulle dekoda en fil på PDP11 så skulle jag läsa in data från skiva i stället för att ha filen i datorns minne. Att använda skiva i stället för minnet fungerar precis lika bra men hastigheten är kanske en tusendel jämfört med att jobba direkt mot minne. PDP11 från 1970-talet skulle tugga länge på en dekodning av en 20 sekunders ljudfil. Gissar någon minut.
Vi börjar nu läsa in värden, ett datavärde i taget från filen som alltså ligger i centralminnet (RAM) och beräknar ett flytande medelvärde över tio ljudvärden. Experiment visade att detta gav en pålitlig detektion. Jag är övertygad om att en annan filtrering skulle fungera lika bra. För en annan ljudfil genererad av en utomstående producemt så skulle vi antagligen behöve experimentera här.
for d in wav_data:
ampl=(9*ampl+abs(d[0]))/10
Vi går nu vidare och ser när vi stöter på ljud och lägger då på minnet vilket ljudvärde 0 … vi hade och kontrollerar samtidigt om vi går från noll (icke ljud) mot ljud (större än ca. 0.1). Vi kan nu skilja på en ljudpuls och en paus. Genom att vi lagrade start och slut på pulsen så kan vi genom subtraktion beräkna längden på en ljudpuls eller en paus. Om vi stötte på en kort ljudpuls så lägger vi till ‘*’ i slutet av variablen my_ch . Om vi stötte på en lång ljudpuls så lägger vi till ‘-‘. Om vi stötte på en mellanlång eller lång paus så vet vi att tecknet är färdigt för översättning. Om vi stöter på en riktigt lång paus så vet vi att ett ord har passerats och då skriver vi ett radbyte för att underlätta läsningen.
Hela detektorn har då följande utseende:
for d in wav_data:
ampl=(9*ampl+abs(d[0]))/10
i=i+1
if((ampl>0.1) and (nosnd==True)):
sstart=i
l = i-pstart
if(l<5000):
sp=0
elif((l>5000) and (l<20000)):
print(translate_char(my_ch)+" "+my_ch)
my_ch=""
else:
print(translate_char(my_ch)+" "+my_ch+"\n")
my_ch=""
snd = True
nosnd = False
elif((ampl<0.01) and (snd==True)):
pstart = i
if((i-sstart)<5000):
my_ch = my_ch + "*"
else:
my_ch = my_ch + "-"
snd=False
nosnd=True
Intresserade läsare kan lyssna på morsekoden nedan. Min reaktion på denna morsemottagare är egentligen att det visade sig vara mycket lättare att skriva mottagaren än jag hade väntat mig.
Om någon läsare vill skriva en mottagare för svårare morsekod t.ex. morsekod där alla tidsvärden varierar då en människa sänder morse så gissar jag att jag skulle spela in alla meddelanden. Därefter skulle jag skriva en dynamisk analysator som gissar längden på kort/långt ljud samt länden av pause. Dv.s. jag skulle mäta längden på alla tidsvärden separat för vatje fil.
En annan komplikation är att signalamplituden sannolikt skulle kunna variera rätt mycket. Även detta skulle kräva separat hantering så att gränsvärdet för ljud/tystnad skulle kunna väljas utgående från signalen i stället för att ges ett fast värde som i detta exemple.
En gammal traditionell morsesändare sänder morse via en radiosändare. Om vi går mer än hundra år tillbaka i tiden så kunde sändningen gå över en enda tråd d.v.s. mellan två punkter vilket är ganska begränsat … så långt tillbaka går vi dock inte.
Om jag vill skicka iväg ett meddelande till i princip hela världen så hur gör jag? Problemet är främst hur jag skall kunna lagra den skapade ljudfilen automatiskt på en åtkomlig plats ute på nätet. Jag hade ursprungligen tänkt mig att jag lagrar filen på spegling.blog men jag råkade ut för en del tekniska komplikationer då jag försökte göra detta automatiskt. Jag kom då på att jag har en urgammal blog http://www.kolumbus.fi/larsil som stöder ftp-protokoll. Jag kan alltså flytta morse ljudfilen till kolumbus servern med ftp på samma sätt som jag flyttade filen från PDP11 till min huvuddator deNeb.
Att flytta en nygenererad morse ljudfil till kolumbus betyder att jag kör ett skript send.ftp som automatiskt flyttar filen upp till kolumbus där den är ”synlig för hela världen”.
#!/bin/bash
HOST=www.kolumbus.fi
USER=xxxxxxxx
PASSWORD=xxxxxxxxxxxx
ftp -inv $HOST <<EOF
user $USER $PASSWORD
put morse_message.mp3
bye
EOF
echo "Cleaning system variables"
unset HOST
unset USER
unset PASSWORD
Orsaken till att jag använder unset HOST etc. är att jag inte vill att dessa systemvariabler skall bli liggande i maskinen trots att maskinen naturligtvis är skyddad. Utan unset kunde en person som har vägen förbi, och terminalfönstret är öppet, får reda på t.ex. kolumbusserverns användarnamn och password genom att ge kommandona:
echo HOST
echo USER
echo PASSWORD
För att översätta en textrad till morse och flytta resultatet till Internet ger jag följande kommandon:
./smorse.run
Skriv text att sända som morse:sssss lars silen sssss
Ord=sssss
s *** ti ti ti
s *** ti ti ti
s *** ti ti ti
s *** ti ti ti
s *** ti ti ti
Ord=lars
l *-** ti taa ti ti
a *- ti taa
r *-* ti taa ti
s *** ti ti ti
--- etc ...
Jag valde att omge namnet med 's' eftersom bokstanen 's' i morsealfabetet är '***' d.v.s. ti ti ti vilket är lätt att känna igen.
Flyttning till servern kolumbus:
./send.ftp
Connected to xxxxxxxxxxxxxxxxxxx
220 ProFTPD Server (Elisa Oyj FTP Service)
331 Password required for xxxxxxxx
230 User xxxxxxxx logged in
Remote system type is UNIX.
Using binary mode to transfer files.
local: morse_message.mp3 remote: morse_message.mp3
200 PORT command successful
150 Opening BINARY mode data connection for morse_message.mp3
226 Transfer complete
169291 bytes sent in 0.10 secs (1.6789 MB/s)
221 Goodbye.
Cleaning system variables
Läsaren kan lyssna på hur morsesändaren låter nedan:
I en tidigare artikel visade jag hur man rätt enkelt kan skapa ett verktyg som möjliggör att tex. barn kan programmera på sitt eget modersmål i detta fall svenska. Språket ”sv” och kompilatorn ”csv” förstår svenska nyckelord och kompileras i två steg. Det första steget producerar c-kod och det andra skedet kompilerar från c-språket till körbar maskinkod (se den tidigare artikeln).
Hela paketet i den tidigare artikeln inkluderande lex-programmet som sköter översättningen från sv till c går på några hundra rader kod. Hur mycket jobb kräver det att modifiera programmen så att de kör på en urgammal Unix samt vilka är de begränsningar som är av sådan art att ny design behövs?
Kända begränsningar i PDP11
En maskin från 1970-talet var konstruerad för en specifikt engelsk/amerikansk miljö utan någon tanke på yttre nationella alfabet. Bokstäverna ÅÄÖ kunde stödas men sällan problemfritt. Jag valde att helt enkelt lämna bort prickar över åäöÅÄÖ d.v.s. texten ser ut som mina handskrivna skoluppsater på 1960-70-talet.
Maskinen stöder inte ljud vilket betyder att sändaren måste modifieras. I praktiken betyder detta att ljudet genereras på en annan (modern) maskin. Morsekoden som sådan lagras i en textfil och flyttas automatiskt till en annan maskin som tolkar den färdiga koden och genererar ljud. Jag kunde skriva kod på PDP11 emulatorn som styr in/ut pinnar på Raspberry Pi men jag uppfattar inte detta vara värt besväret.
Oväntade små problem
Det första problem jag stötte på var att det program lex genererade från swe.lex –> lex.yy.c inte kompilerade på PDP11 trots att jag körde en lex version som hörde hemma i BSD 2.11. Vad hände?
Jag kom inte ihåg att enradiga kommentarer ”// … till slutet av rad” är ett nytt påhitt. Jag löste problemet genom att ta bort denna typ av kommentarer. Samma sak måste göras med morseprogrammet. Det är naturligtvis möjligt att definiera om swe.lex så att jag genererar den gamla typens kommentarer i stället för nya enradiga. Detta blir en övning för framtiden.
Urgamla versioner av C-språket deklarerar parameterlistor till funktioner på ett annat sätt än moderna versioner. Ett exempel på detta är om jag vill läsa in någon parameter från kommandoraden.
I modern C-kod skulle jag deklarera kommandoradsparametrar på följande sätt:
Samma modifikation som i det senare exemplet måste jag göra för alla funktionsanrop som har parameterlista.
Funktionen getline som finns färdig i stdio.h i moderna varianter av C-språket eller egentligen i moderna varianter av C-biblioteket. Denna färdiga funktion introducerades ungefär 2010 d.v.s. långt efter att man slutade uppdatera min BSD 2.11. Lösningen är naturligtvis att skriva funktionen själv. Jag utgick från boken ”The C Programming Language” av Brian W. Kernighan och Dennis M. Ritchie. Boken är en klassiker! Min nya funktion fick följande utseende i språket sv:
Jag märker att jag använde return i stället för returnera vilket dock är ok eftersom return i såfall faller igenom oöversatt vilket ger korrekt C-språk … Notera att parametrarna är deklarerade på gammalt vis. Notera hur man gör två saker samtidigt i upprepa-slingan. Jag läser in ett tecken ‘c’ och kontrollerar samtidigt att inte filen har tagit slut. Detta kallas bieffekt och är något man försöker undvika i de flesta programmeringsspråk eftersom bieffekterna kan ge upphov till programmeringsfel som kan vara besvärliga att hitta om en bit programkod t.ex. förutom en tydlig jämförelse också ändrar värdet på en variabel.
Programmet kompilerar
Jag plockar bort ljudrutinerna i programmet som kör på PDP11 d.v.s. aplay eftersom det inte finns något ljudstöd.
Då programmet kompilerar första gången vet jag att jag börjar vara nära målet. Provkörning visade att den text jag matade in via getline splittrades upp i ord helt korrekt men vid körning fick jag diverse skräp efter det sista ordet. Problemet berodde på funktionen strtok som delar upp en sträng i en serie segment separerade av en eller flera separatorer i den gamla versionen ville ha två separatorer d.v.s. mellanslag ‘ ‘ och radbyte. I den nya C-versionen behövdes endast mellanslag som separator.
Då kompileringen går igenom märker jag att det inte lönar sig att kompilera om swe.lex varje gång eftersom kompileringen av lex.yy.c till programmet sv tar kanske 20 sekunder i stället för en blinkning under Linux på min normala PC. Lösningen är naturligtvis att kompilera om sv endast då detta behövs.
Då jag kör morseprogrammet blir resultatet:
./smorse
Skriv text att sanda som morse:lasse skriver
*-**
*-
***
***
*
+
***
-*-
*-*
**
***-
*
*-*
+
Tecknet ‘+’ betyder att det är en lång paus på 0.7 sekunder mellan ord.
Morsesekvensen ovan skickar jag i stället till en fil s.morse som jag sedan kan skicka vidare till morsesändaren på en annan maskin d.v.s. min Linux PC. Jag skriver ett enkelt shellskript som kör morseprogrammet och automatiskt skickar resultatet med ftp till min Linuxmaskin.
echo "Enter the text to send:"
./smorse >s.morse
sh send.ftp
Skriptet send.ftp använder ftp som har diskuterats tidigare för att skicka filen s.morse till Linuxmaskinen. Skriptet send.ftp har följande utseende:
ftp -inv $HOST <<EOF
user $USER $PASSWORD
put s.morse
bye
EOF
Jag har definierat systemvariablerna HOST, USER och PASSWORD som jag behöver för att kunna logga in på Linuxmaskinen. Filen morse.txt läggs för närvarande hemkatalogen men jag ändrar detta senare till att peka in till en egen katalog för sändaren. Från linux kan jag sedan med hjälp av ett enkelt litet program skicka resultatet vidare med epost som text eller skicka ljudet vidare tex. med radio. Det var roligt att se att det var enkelt att automatisera ftp-funktionen på PDP11.
Jag skrev en enkel morsetolk/sändare som kontinuerligt väntar på meddelanden att sända på min bordsdator deNeb. Programmet är listat nedan. Jag skrev på skoj programmet i programspråket Python som idag är en väldigt populär ersättare till forntidens Basic. Programmet sender.py visar hur man i Python kan generera ljud men också hur man enkelt kan använda kommandon ur operativsystemet eller något annat program på maskinen. Jag anropar operativsystemet för att kontrollera om det har kommit in något nytt sändningsjobb från PDP11 och putsar i såfall bort det gamla meddelandet. Programmet aplay genererar ljud till högtalarna och programmet ffmpeg skapar en ljudfil innehållande hela ljudsekvensen med bättre tidsprecision än anropen till aplay. Det tar ett ögonblick att starta upp aplay vilket gör timingen inexakt. Det kompletta meddelandet finns i ljudfilerna morse_message.wav samt i den komprimerade filen morse_message.mp3 . Vill man spara utrymme kan kvaliteten sänkas betydligt utan att meddelandet blir oläsligt. De råa ljudfilerna är så stora att de inte ryms i PDP11 normala användarminne (ca. 400 kb då ljudfilerna är 1.7 MByte och den packade mp3 filen är 462 kByte. I en 30 Euros Raspberry Pi läser man utan att blinka in ljudfilerna och behandlar dem i minnet om detta behövs. På 1970-talets PDP11 skulle man ha kört från skiva till skiva och behandlat små minnessegment och successivt skrivit data till skiva eller magnetband.
#!/home/lasi/miniconda3/bin/python
# Modify the python used to match your system (first line). Check with "which python".
# Name=sender.py
# The program "sends" morse code produced by the PDP11
# and automatically transferred to deNeb by ftp.
# This program checks if the file s.morse exists and
# if that is the case sends the morse code, deletes the
# morse message and then starts looking for the next message
# Author: Lars Silen
# This is free code. Feel free to use or modify on your own risk.
import os
import time
from os.path import exists
run = True
def send_morse(line):
for i in range(0,len(line)):
if line[i]=='*':
os.system("aplay 0_1.wav")
os.system("aplay sp.wav")
os.system('echo "file 0_1.wav" >>wav_files.txt\n')
os.system('echo "file sp.wav" >>wav_files.txt\n')
elif line[i]=='-':
os.system("aplay 0_3.wav")
os.system("aplay sp.wav")
os.system('echo "file 0_3.wav" >>wav_files.txt\n')
os.system('echo "file sp.wav" >>wav_files.txt\n')
elif line[i]=='\n':
os.system("aplay cp.wav")
os.system('echo "file cp.wav" >>wav_files.txt\n')
elif line[i]=="+":
os.system("aplay wp.wav")
os.system('echo "file wp.wav" >>wav_files.txt\n')
while run:
os.system("rm wav_files.txt")
if exists("s.morse"):
os.system("rm s.morse.old")
os.system("rm morse_message.wav")
os.system("rm morse_message.mp3")
f=open("s.morse","r")
lines = f.readlines()
# print(lines)
for i in range(2,len(lines)):
send_morse(lines[i])
os.system("mv s.morse s.morse.old")
# Create a wav file containing the audio of the message
os.system("ffmpeg -f concat -i wav_files.txt -c copy morse_message.wav")
os.system("ffmpeg -i morse_message.wav -vn -ar 44100 -ac 2 -b:a 192k morse_message.mp3")
print("Generated audio message! Listen to: morse_message.wav or morse_message.mp3")
else:
print("Sleep 5 seconds")
time.sleep(5)
os.system("clear")
En intressant jämförelse mellan det ursprungliga morseprogrammet kompilerat via C till maskinkod är att man hör skillnad mod Pythonprogrammets direkta ljudgenerering. Pythonprogrammet kör hörbart långsammare vilket i sig är naturligt då Python är ett tolkat språk som kör kanske 20 ggr långsammare än kompilerad C-kod.
Jag brukar spela folkmusik på fredagarna inne i Helsingfors centrum och jag passade på att vandra kanske en kilometer tillsammans med en annan spelman för att titta på demonstrationen. Min personliga upplevelse var att det var folkfest och människorna var glada. Jag såg två personer som var ordentligt berusade vilket inte är mycket då det är fredag kväll. Den ena var en dam som var så berusad att hon inte hölls på benen och som behövde hjälp då hon ville sova ruset av sig i en snödriva. Den andra individen står på bilen i bilden nedan. Det var blixthalt på bilen och egentligen ett under att hen inte ramlade ner … det fanns naturligtvis vindrutetorkare som hen höll i … tvivlar på att de efter den behandlingen längre torkar speciellt bra.
Jag kommer i denna artikel att visa hur jag enkelt kan skapa en svenskspråkig variant av programmeringsspråket C, språket kallar jag sv och kompilatorn blir då csv. Notera att avsikten med denna övning är att illustrera hur enkelt det vore att erbjuda en nationell nybörejarplattform för unga programmerare. För att verifiera programspråket sv skriver jag ett program som läser in en textsträng och sänder resultatet som morsekod. Morsekoden visas också i textform. Följande steg blir att undersöka vilka förändringar jag behöver göra i koden för att programmet skall fungera på min emulerade minidator PDP11/70 som kör en gammal BSD Unix 2.11 från början av 1990-talet. Unix utvecklades i tiden på minidatorn PDP11 som klarade av att hatera flera användare på olika terminaler allt detta på en maskin med 4 MB (4 miljoner byte) minne. En modern hemdator har typiskt 2000 gånger mera minne … eller ännu mer.
Kompilering av ett program skrivet i sv görs på någon sekund. Jag kompilerar morsesändaren smorse.sv dock utan filtyp eftersom mitt kompileringsskript förenklas en aning om jag inte behöver kontrollera filtypen utan kan anta att användaren vet vad hen gör.
./csv smorse Källkod:smorse.sv Översättaren är definierad i swe.lex Kompilerar översätteren swe.lex till c-kod Kompilerar lex analysatorn till körbar maskinkod: sv Översätter sv-programmet smorse.sv till c-kod: smorse.c C-kod finns nu i smorse.c Kompilerar nu till körbar maskinkod! The executable is: smorse.run
Jag kan nu köra programmet med smorse.run
Notera att morsesändningen i ljudfilen är en annan än på skärmen ovan. En utmaning för lyssnare är att bena ut vad som sänts!
Texten nedan visar hur ”kompilatorn” för språket sv är konstruerad. Jag skriver därefter programmet smorse i språket sv för att verifiera att kompileringen fungerar. Notera att programmet på min Linux-dator genererar hörbar morsekod. PDP11 har inte ljudstöd varför jag tänker generera ett simulerat magnetband som huvuddatorn kan sända som ljud.
En elev som lär sig att programmera kommer att stöta på flera samtidiga utmaningar. Vid programmering dyker det upp nya begrepp såsom ”variabel”, ”fil”, ”adress” och många andra begrepp som inte är bekanta från vardagslivet. Eleven lär sig också ett nytt språk, mycket enkelt dock, som beskriver logiken i programmet. Det språk som ligger under de flesta programmeringsspråk idag är engelska. Om vi börjar undervisa tex. en 10-12 årig elev programmering så kan engelskan som sådan vara ett visst problem som kan göra det svårare för eleven att komma över den första tröskeln in i programmeringens värld.
En enkel lösning på problemet programmering på ett främmande språk är naturligtvis att vi i inledningsaskedet skulle låta eleverna programmera på svenska/finska/norska/estniska för att därefter då grunderna finns gå över till engelska som idag är en de facto standard.
Skulle programmering på t.ex. svenska kräva våldsamma ekonomiska resurser? Är inte utveckling av ett nytt programmeringsspråk samt kompilator för det ”nya” språket extremt dyrt? Svaret är att en enkel tvåstegskompilator kan skrivas i ungefär hundra rader kod … inte dyrt alltså!
Om någon läsare är intresserad av att experimentera med språket sv eller modifiera det för något annat språk så kan det löna sig att ta kontakt via en kommentar så skickar jag alla filerna som ett paket med epost. Jag gör inte dessa förfrågningar synliga. Programlistningar på vebben tenderar att vara opålitliga vilket kan leda till onödig felsökning om man kopierar koden direkt från skärmen.
Språket ”sv” samt kompilatorn ”csv”
Min emulerade PDP11/70 minidator kör idag på mitt arbetsbord och jag måste således hitta på något vettigt leksaksprojekt. Jag kör BSD Unix v2.11 på PDP11:an vilket betyder att jag har tillgång till i princip samma programmeringsverktyg som på min huvuddator d.v.s. en kompilator för språket ”c” (kompilatorn heter cc) samt verktyget lex (lex har jag använt mycket sällan).
Ett trevligt miniprojekt kunde då vara att skapa ett svenskt programmeringsspråk som strukturellt är identiskt med programmeringsspråket ”c” under Unix/Linux. Tanken är att det skall vara möjligt att koda helt i ”sv” eller koda i en hybridmiljö där det är möjligt att använda ”c” direkt utan att programmets funktion påverkas. Tanken är att översätta ”sv” till normalt ”c” som därefter kompileras till maskinspråk som vilket normalt c-program som helst.
Fördelen med att använda c som mellanliggande språk är naturligtvis at jag inte behöver skriva den egentliga kompilatorn och maskinkodsgeneratorn (jag har för många år sedan skrivit ett komplett programmeringsspråk ”sil=simple language). Problemet är alltså att skriva en översättare från språket sv till språket c.
Unix ger tillgång till två klassiska verktyg för att skapa kompilatorer lex (lexical analyzer) och yacc (yacc=yet another compiler compiler). Jag har aldrig tidigare aktivt använt någondera. Programmet ”lex” kan enkelt sköta översättningen från sv till c d.v.s. jag behöver inte yacc eftersom min kompilator redan finns under förutsättning att det program lex producerar förmår att skapa kompilerbar c-kod.
Jag definierar ett antal ”REGLER” i lex som beskriver hur t.ex. ett nyckelord, en kommentar, en textsträng o.s.v. definieras. Då en regel passar in på källtexten skriver mitt genererade analysatorprogram ut motsvarande element för språket c.
Då jag skriver min översättare från sv till c i lex blir programmets längd ungefär hundra rader kod d.v.s. programmet är väldigt litet och överskådligt. Mitt sv-språk är i detta skede ett subset av språket c men redan i nedanstående form kan man skriva riktiga program i sv. Språket kan enkelt utvidgas genom att modifiera filen swe.lex. Då jag använder lex för att kompilera min definition av sv blir resultatet ett c-program som heter lex.yy.c . Jag kompilerar därefter lex.yy.c till ett körbart program sv som sköter översättningen av en källkodsfil i sv till motsvarande c-program.
Lex-program för översättning av sv till c
Filen swe.lex kan enkelt modofieras så att en större del av c-språket stöds. Notera att jag har skrivit swe.lex så att resulterande c-filen som ett sv-program översätts till har exakt samma antal rader som källkoden i sv. Detta betyder att då jag kompilerar mitt sv program så stämmer radnumren för felmeddelanden för både sv och c.
Min definition av sv-språket ser ut på följande sätt:
%{
/* A lexical analyzer for the computer language "sv". This is a simple translation */
/* of the "c" language into swedish. The corresponding "compiler" translates a */
/* sv-source into c-language that can be compiled using an ordinary c-compiler */
/* need this for the call to atof() below */
#include <math.h>
/* need this for printf(), fopen() and stdin below */
#include <stdio.h>
%}
WHITESPACE [ \t\n]+
DIGIT [0-9]
ID [a-zA-Z][a-zA-Z0-9]*
CHAR [a-zåäö][A-ZÅÄÖ][0-9][\ ][!?][\n]
COMMENT \/\/.*[\n]
STR1 \".[\\]*\"
APP [\"]
LPAR [(]
RPAR [)]
LWAV [{]
RWAV [}]
TERMINATOR [;]
EXCL [!]
AE [Ä]
ae [ä]
Aring [Å]
aring [å]
COMMA [,]
%%
{DIGIT}+ printf("%d",atoi(yytext));
{DIGIT}+"."{DIGIT}* printf("%s", yytext);
{STR1} printf("%s",yytext);
{LPAR} printf("%s",yytext);
{RPAR} printf("%s",yytext);
{LWAV} printf("%s",yytext);
{RWAV} printf("%s",yytext);
{EXCL} printf("!");
{COMMA} printf(",");
#inkludera printf("#include");
#definiera printf("#define");
program printf("\nmain");
funktion printf(" ");
resultat printf("return ");
alternativ printf("switch");
valt printf("case ");
bryt printf("break");
om printf("if ");
medan printf("while");
upprepa printf("for");
annars printf("else ");
skrivf printf("printf");
skrivr printf("printf");
fskrivf printf("fprintf");
hämtarad printf("getline");
hämta printf("get");
sätt printf("put");
läs printf("read");
läsrd printf("readln");
dröj printf("delay");
heltal printf("int ");
tecken printf("char ");
byte printf("byte ");
sanningsvärde printf("boolean ");
register printf("int");
bitmask printf("int");
likamed printf("==");
mindre_än printf("<");
mindre_än_eller_likamed printf("<=");
större_än printf(">");
större_än_eller_likamed printf(">=");
och printf("&&");
binär_och printf("&");
and printf("&");
or printf("|");
xor printf("^");
binär_exclusiv_och printf("^\n");
vflytta printf("<<");
hflytta printf(">>");
storlek_t printf("size_t");
\<\< printf("<<");
\>\> printf(">>");
= printf("=");
\< printf("<");
\> printf(">");
\. printf(".");
\&\& printf("&&");
\& printf("&");
{ID} printf("%s", yytext);
{TERMINATOR} printf("%s",yytext);
{COMMENT} printf("%s",yytext);
{WHITESPACE} printf("%s",yytext);
"+"|"-"|"*"|"/" printf("%s", yytext);
"{"[^}\n]*"}" /* eat up one-line comments */
%%
int main(int argc, char *argv[])
{
++argv, --argc; /* skip over program name */
if (argc > 0)
yyin = fopen(argv[0], "r");
else
yyin = stdin;
yylex();
return(0);
}
Verifiering av språket ”sv”
Ett enkelt sätt att visa att det nya språket ”fungerar” är naturligtvis att skriva ett riktigt program i programspråket sv. Jag byggde för kanske tjugo år sedan några led-ficklampor med några barnhemsbarn där vi använde en liten mikroprocessor som programmerades i mitt språk ”sil” (simple language) för Microchips processor 16F84. Ficklamporna programmerades så att de olika barnens ficklampor kunde blinka ägarens namn i morsekod.
Nedan visar jag hur man kan skriva ett program i språket sv som läser in en textrad från användaren och ”sänder” texten som morsekod till skärmen men också som morseljud via datorns högtalare. Jag kommer att flytta programmet till PDP11 och något modifiera det så att PDP11 som saknar högtalare i stället skickar ett magnetband till huvuddatorn för sändning, detta beskrivs eventuellt i en senare artikel.
Morsesändare skriven i sv
En morseöversättare gör man enklast så att man tabellerar tecknen ”A-Z”, ”a-z” samt siffrorna 0-9 samt deras motsvarande teckenkoder. För en specifik bokstav vill vi alltså ha en översättarfunktion skrivMorse() av ungefär följande typ (ti=’*’ och taa=’-‘):
heltal skrivMorse(tecken c){ heltal i; tecken morse[16]; alternativ (c){ valt ‘a’: strcpy(morse, ”-”); bryt;
valt ‘b’: strcpy(morse,”-”); bryt; valt ‘c’: strcpy(morse,”–”); bryt; valt ‘d’: strcpy(morse,”-”); bryt; valt ‘e’: strcpy(morse,”*”); bryt; … } skrivf(”Morsekod:%s\n”,morse); …
Som indata till vår funktion ”skrivMorse” ges ett tecken/en bokstav ”c” vid anrop till funktionen. Resultatet av översättningen finns efter exekvering nu i variabeln ”morse”. Jag antar att funktionen är ganska läslig även för personer som inte kan programmera. Nyckelordet ”bryt” betyder att rätt alternativ hittades och exekveringen fortsätter vid ”skrivf(…). Om vi vill översätta bokstaven ”s” till morse så anropar vi vår funktion med:
skrivMorse(‘s’);
Resultatet skulle bli Morsekod:***
Vi börjar vårt egentliga program med att låta programmet be om en text att sända samt läsa in en textrad som innehåller texten. Funktionen skrivf() skriver ut text som kan formatteras för heltal, flyttal etc. Vi kan göra detta med:
skrivf(”Skriv text att sända som morse:”); l=hämtaRad(&line,&len,stdin);
Kommandot ”hämtaRad” använder biblioteksfunktionen ”getline” som finns definierad i biblioteket stdio.h. Vi måste då komma ihåg att deklarera att vi använder biblioteket stdio.h . Vi inkluderar ett standardbibliotek med:
#inkludera <stdio.h>
Vårt program har nu ungefär följande utseende och det utför inte ännu något vettigt :
#inkludera <stdio.h>
#inkludera <stdlib.h>
#inkludera <string.h>
heltal skrivMorse(tecken c){ heltal i; char morse[16]; alternativ (c){ valt ‘a’: strcpy(morse, ”-”); bryt; valt ‘b’: strcpy(morse,”-**”); bryt; … fler definitioner av morsekoder … } }
heltal program(){ heltal l=0; storlek_t len=0; tecken *rad=NULL; skrivf(”Skriv text att sända som morse:”); l=hämtarad(&rad,&len,stdin); // Skriv ut den lästa raden för att verifiera att inläsningen lyckades skrivf(”Inläst rad:%s\n”,rad); }
Variablerna l, len och *rad behövs för anropet till hämtarad().
Då vi skriver in vår text som skall skickas så vill vi gärna hantera texten ordvis d.v.s. vi skickar ett ord i taget och genererar en standardiserad paus mellan orden. För att splittra up vår textsträng i separata ord inkluderar vi biblioteket string (#inkludera <string.h> se ovan). String-biblioteket har en användbar funktion strtok() som splittrar upp den text vi ger som funktionsparameter i en tabell med separata textsträngar (ordsträngar) separerade med mellanslag ‘ ‘. Råtexten bryts alltså vid mellanslag. Jag splittrar upp den ingående råtexten genast då jag deklarerar ordtabellen som jag kallar ett_ord:
tecken *ett_ord = strtok(rad,” ”);
Om jag har matat in texten ”Lasse skickar morse” så kommer ett_ord efter anrop att innehålla textsträngar som jag kommer åt med:
Vi kan nu skriva en ny funktion som vi kallar skicka_text_som_ord(”någon text …”) .
heltal skicka_text_som_ord(tecken rad[]){ heltal i; tecken *ett_ord = strtok(rad,” ”); medan (ett_ord != NULL){ skrivf(”Ord=%s\n”,ett_ord); upprepa(i=0; i<strlen(ett_ord);i++){ // Skriv ett tecken i nuvarande ord skrivMorse(ett_ord[i]); system(teckenpaus); skrivf(”\n”); } skrivf(”\n”); ett_ord = strtok(NULL, ” ”); } }
Efter att vi splittrade upp råtexten i ord så tar vi ett ord i taget och splittrar upp det i bokstäver som skickas för konvertering till morse.
Vi går igenom alla orden i vår råtext med:
medan (ett_ord != NULL){ skrivf(”Ord=%s\n”,ett_ord); … }
Motsvarande konstruktion i språket c är ”while(ett_ord != NULL){ … }” . Vi skickar vidare orden för sändning så länge som ett_ord inte är tomt (NULL).
Vi lägger nu till en slinga för att skicka iväg varje ord bokstav för bokstav för översättning till morse och sändning. Slingan har följande utseende:
upprepa(i=0; i<strlen(ett_ord);i++){
// Skriv ett tecken i nuvarande ord
skrivMorse(ett_ord[i]);
system(teckenpaus);
skrivf("\n");
}
Vi använder konstruktionen ”upprepa” som motsvarar c-språkets ”for” slinga. Slingan går igenom ordsträngen ett_ord bokstav för bokstav tills vi har nått den fulla längden på strängen ett_ord.
Slingan stegar alltså igenom ett_ord på följande sätt:
i=0 ett_ord[i] = ‘L’ som skickas till skrivMorse(‘L’) i=1 ett_ord[i] = ‘a’ som skickas till skrivMorse(‘a’) i=2 ett_ord[i] = ‘s’ som skickas till skrivMorse(‘s’) i=3 ett_ord[i] = ‘s’ som skickas till skrivMorse(‘s’) i=4 ett_ord[i] = ‘e’ som skickas till skrivMorse(‘e’)
Efter att vi har skickat ett helt ord så håller vi paus genom att anropa operativsystemets funktion sleep.
Vi låter systemet sova i 0.7 sekunder mellan ord. Sovtiden mellan bokstäver är 0.1 sekunder.
Vi spelar upp ”tit” och ”taa” under Linux så att jag med hjälp av programmet ”Audacity” genererade en ton med frekvensen 880 Hz. Från denna ton klippte jag två stumpar 0.1 repektive 0.3 sekunder långa som jag sparade som ljudfilerna 0_1.wav samt 0_3.wav . Jag kan spela upp en wavfil under Linux med hjälp av programmet ”aplay”.
Programmet i dess helhet (under linux i detta skede) har då följande utseende:
// Morse
// Programspråket "sv" är språket "c" med svenska kommando-ord.
// Språket översätts till standard "c" som sedan kompileras till maskinspråk
// för att köras.
// Språket "sv" är egentligen ett experiment med Unixverktyget "lex" som
// har konstruerats för att känna igen ord och strukturer i en text.
// Strukturer som hittas skulle normalt skickas vidare till programmet "yacc"
// (yet another compiler compiler = en annan kompilator kompilator).
// Eftersom jag översätter språket "sv" till "c" så behöver jag inte
// någon kompilator eftersom denna redan finns och likaså behöver jag inte
// någon kodgenerator som skulle generera maskinspråk eftersom även den redan
// finns. Notera att jag kan använda c-språk direkt om motsvarande
// sv-konstruktion inte har definierats.
// Notera att endast en delmängd av SV-C har skrivits.
// Vill man ha en mera fullständig
// motsvarighet så måste filen swe.lex utvidgas med nya nyckelord.
// Jag kör för närvarande en emulerad minidator PDP11/70 från 1970-talet.
// Operativsystemet är BSD Unix 2.11.
// Detta är ett experiment i att skriva ett enkelt svenskt
// programmeringsspråk som är körbart på denna urgamla dator.
//
// Lars Silen 2022
// Detta är öppen källkod som fritt får distribueras
// Författaren tar inget ansvar för eventuella fel i genererad kod
#inkludera <stdio.h>
#inkludera <stdlib.h>
#inkludera <string.h>
// Definiera tidslängden på olika element i Morse
tecken teckenpaus[] = "sleep 0.1";
tecken ordpaus[] = "sleep 0.7";
heltal skrivMorse(tecken c){
heltal i;
char morse[16];
alternativ (c){
valt 'a': strcpy(morse, "*-"); bryt;
valt 'b': strcpy(morse,"-***"); bryt;
valt 'c': strcpy(morse,"-*-*"); bryt;
valt 'd': strcpy(morse,"-**"); bryt;
valt 'e': strcpy(morse,"*"); bryt;
valt 'f': strcpy(morse,"**-*"); bryt;
valt 'g': strcpy(morse,"--*"); bryt;
valt 'h': strcpy(morse,"****"); bryt;
valt 'i': strcpy(morse,"**"); bryt;
valt 'j': strcpy(morse,"*---"); bryt;
valt 'k': strcpy(morse,"-*-"); bryt;
valt 'l': strcpy(morse,"*-**"); bryt;
valt 'm': strcpy(morse,"--"); bryt;
valt 'n': strcpy(morse,"-*"); bryt;
valt 'o': strcpy(morse,"---"); bryt;
valt 'p': strcpy(morse,"*--*"); bryt;
valt 'q': strcpy(morse,"--*-"); bryt;
valt 'r': strcpy(morse,"*-*"); bryt;
valt 's': strcpy(morse,"***"); bryt;
valt 't': strcpy(morse,"-"); bryt;
valt 'u': strcpy(morse,"**-"); bryt;
valt 'v': strcpy(morse,"***-"); bryt;
valt 'w': strcpy(morse,"*--"); bryt;
valt 'x': strcpy(morse,"-**-"); bryt;
valt 'y': strcpy(morse,"-*--"); bryt;
valt 'z': strcpy(morse,"--**"); bryt;
// Lägg till ÅÄÖ här om du behöver dem
valt 'A': strcpy(morse, "*-"); bryt;
valt 'B': strcpy(morse,"-***"); bryt;
valt 'C': strcpy(morse,"-*-*"); bryt;
valt 'D': strcpy(morse,"-**"); bryt;
valt 'E': strcpy(morse,"*"); bryt;
valt 'F': strcpy(morse,"**-*"); bryt;
valt 'G': strcpy(morse,"--*"); bryt;
valt 'H': strcpy(morse,"****"); bryt;
valt 'I': strcpy(morse,"**"); bryt;
valt 'J': strcpy(morse,"*---"); bryt;
valt 'K': strcpy(morse,"-*-"); bryt;
valt 'L': strcpy(morse,"*-**"); bryt;
valt 'M': strcpy(morse,"--"); bryt;
valt 'N': strcpy(morse,"-*"); bryt;
valt 'O': strcpy(morse,"---"); bryt;
valt 'P': strcpy(morse,"*--*"); bryt;
valt 'Q': strcpy(morse,"--*-"); bryt;
valt 'R': strcpy(morse,"*-*"); bryt;
valt 'S': strcpy(morse,"***"); bryt;
valt 'T': strcpy(morse,"-"); bryt;
valt 'U': strcpy(morse,"**-"); bryt;
valt 'V': strcpy(morse,"***-"); bryt;
valt 'W': strcpy(morse,"*--"); bryt;
valt 'X': strcpy(morse,"-**-"); bryt;
valt 'Y': strcpy(morse,"-*--"); bryt;
valt 'Z': strcpy(morse,"--**"); bryt;
// Lägg till åäö här om du behöver dem
valt '1': strcpy(morse,"*----"); bryt;
valt '2': strcpy(morse,"**---"); bryt;
valt '3': strcpy(morse,"***--"); bryt;
valt '4': strcpy(morse,"****-"); bryt;
valt '5': strcpy(morse,"*****"); bryt;
valt '6': strcpy(morse,"-****"); bryt;
valt '7': strcpy(morse,"--***"); bryt;
valt '8': strcpy(morse,"---**"); bryt;
valt '9': strcpy(morse,"----*"); bryt;
valt '0': strcpy(morse,"-----"); bryt;
// Lägg till skiljetecken etc här
}
// Skriv bokstaven som sänds (finns som variabelparametern "c" vid anropet)
skrivf("%c ",c);
skrivf("%s ",morse);
// Generera ljud
upprepa(i=0; i<strlen(morse);i++){
om (morse[i] == '*'){
skrivf("ti ");
system("aplay -q 0_1.wav >/dev/null");
} annars {
skrivf("taa ");
system("aplay -q 0_3.wav >/dev/null");
}
// skrivf("\n");
}
}
heltal skicka_text_som_ord(tecken rad[]){
heltal i;
tecken *ett_ord = strtok(rad," ");
medan (ett_ord != NULL){
skrivf("Ord=%s\n",ett_ord);
upprepa(i=0; i<strlen(ett_ord);i++){
// Skriv ett tecken i nuvarande ord
skrivMorse(ett_ord[i]);
system(teckenpaus);
skrivf("\n");
}
skrivf("\n");
ett_ord = strtok(NULL, " ");
}
}
heltal program(){
heltal l=0;
storlek_t len=0;
tecken *rad=NULL;
skrivf("Skriv text att sända som morse:");
l=hämtarad(&rad,&len,stdin);
skicka_text_som_ord(rad);
}
Den genererade c-koden är strukturellt identisk med sv-programmets kod d.v.s. vi gör en ord för ord översättning. Detta betyder att c-kompilatorn ger felmeddelanden som pekar till rätt rad också i sv källkoden. Min editor bör naturligtvis konfigureras så att den visar radnummer för att felsökning skall vara effektiv.
Översättaren bör sannolikt expanderas med ytterligare c-konstruktioner. Det är oklart i hur hög utsträckning det är värt att översätta funktioner i bibliotek men exemplet ”hämtaRad” visar att detta naturligtvis är möjligt. Det är naturligtvis också möjligt att översätta namnen på standardbiblioteken på samma sätt men knappast vettigt eftersom målet är att eleven också bekantar sig med c-språket och dess bibliotek.
Oversättarprogram komplett:
#!/bin/bash
# Name=csv
# Detta är en kompilator för programspråket "sv" som är en svensk översätytning av språket "c".
# Språket "sv" kan enkelt utvidgas genom att modifiera filen "swe.lex".
# Användning: ./csv program
# Notera att källkoden antas vara program.sv .
# Resultatet blir det körbara programmet program.run
#
# En textfil som är en översättning till språket "c" genereras som program.c .
# Lars Silen 2022
# Detta är fri källkod som fritt får användas och modifieras på egen risk.
echo "Källkod:"$1.sv
echo "Översättaren är definierad i swe.lex"
echo "Kompilerar översätteren swe.lex till c-kod"
lex swe.lex
echo "Kompilerar lex analysatorn till körbar maskinkod: sv"
gcc lex.yy.c -ll -o sv
echo "Översätter sv-programmet " $1.sv " till c-kod: " $1.c
./sv $1.sv >$1.c
echo "C-kod finns nu i " $1.c
echo "Kompilerar nu till körbar maskinkod!"
gcc $1.c -o $1.run
echo "The executable is:" $1.run
Notera att skriptet kompilerar om swe.lex varje gång. Användaren kan alltså enkelt lägga till nya definitioner som blir en del av språket. Om användaren uppfattar att språkdefinitionen är stabil så kan man naturligtvis lämna bort raderna lex swe.lex samt gcc lex.yy.c -ll -o sv , tidsvinsten blir dock marginell.
Jag har under en tid bekantat mig med en emulerad/simulerad PDP11 minidator från mitten av 1970-talet. PDP11 datorn var mycket populär innan IBM PC:n slog igenom och i praktiken sopade bort konkurrenterna mot slutet av 1980-talet då minidatorn PDP11 redan hade kring tjugo år på nacken. Konstruktionen kom att kopieras på olika håll bl.a. tillverkade man kopior i Sovjetunionen t.ex. Electronica 60 som jag tittade på i slutet av 1980-talet som alternativ för kontroll av mätsystem för export till Sovjetunionen. Jag jobbade aldrig med en rysk dator eftersom det visade sig att vi kunde kringgå exportrestriktionerna genom att byta ut en HP 9836 dator baserad på Motorola 68000 processor, som omfattades av amerikanska restriktioner, mot en standad 8 MHz långsam första generationens PC 8088. Jag kommer inte ihåg vilken tillverkares PC vi använde men detta är inte viktigt eftersom de olika PC:na var lika som bär. Lösningen var säkerligen bra eftersom Electronica 60 torde ha haft en hel del problem med pålitligheten. Det skulle dock ha varit roligt att ha fått konkret erfarenhet av dåtidens PDP11.
Den PDP11 jag skriver om är en emulerad PDP11/70 från ungefär 1975 som hörde till den tidsperiodens tungviktare använd som laboratoriepersondator. Datorn kunde köra UNIX och den orkade med flera användare eftersom en PDP11/70 med max minne på 4 MByte kunde stöda flera samtidiga användare. Användarna har under 2.11BSD Unix tillgång till något mer än 300 kByte minne vilket på den tiden var mycket. En PC som lanserades ett antal år senare kunde ha 64 kB – 256 kB (-640kB) för användare och operativsystem. Eftersom det normalt inte fanns något grafiskt användargränssnitt så var minnesbehovet litet och det gick att skriva stora program i 300 kByte. Dagens persondatorers behov av ett stort minne 2000-4000 ggr större än PDP11:ns är en följd av den mycket sofistikerade grafiken som kräver väldigt mycket minne utan att egentligen ge annat mervärde än bling bling. Samma kommentar gäller själva processorn som klockades på några megaherz. Moderna datorer kör med en klocka som tickar igen kanske 1000 ggr snabbare. Det intressanta är dock att då man håller sig till en text-terminal och använder kommandoraden så känns maskinen väldigt OK.
Hur emuleras en antik dator
Redan på slutet av 1960-talet d.v.s. för mer än 50 år sedan skrevs den första emulatorn MIMIC som bl.a. användes för testning och utveckling av nya datorkonstruktioner. 1993 startades projektet simH för att bevara minnet av ålderdomlig hårdvara och program. Den första generationens hårdvara höll snabbt på att försvinna och mängder av data som lagrats på magnetband riskerade att förstöras tex. 1960-talets data från månprojektet. Programmet simH emulerar en mängd gamla datorer bl.a.:
Det är intressant att konkret se hur extremt mycket mera processorkapacitet vi har tillgång till idag, nästan gratis, än för femtio år sedan. En PDP11/70 kostade med fullt utbyggt minne mer än en högklassig ny personbil medan min på en Raspberry Pi emulerad PDP11/70 med maximalt minne en mängd operativsystem etc. kostar kanske 50E (500 SEK). Min emulerade maskin kör dessutom ungefär dubbelt snabbare än orginalet. Min Raspberry Pi har en kapacitet där RAM-minnet är 1000 ggr större än orginalet. Massminnet (skivminnet) är kanske 10000 ggr större och processorns hastighet är kanske 1200 ggr högre än orginalets. Ordlängden i PDP11 var 16 bitar medan en Raspberry Pi kör med ordlängden 64 bitar d.v.s. 4 ggr längre. Totalt kan man eventuellt säga att dagens lilla Raspberry Pi, beroende på vilken applikation man betraktar har en kapacitet som är mellan 1000 och 1000000 ggr högre än 1970-talets PDP11. Sannolikt ligger sanningen närmare 1000000 ggr än 1000 ggr …
Hello world
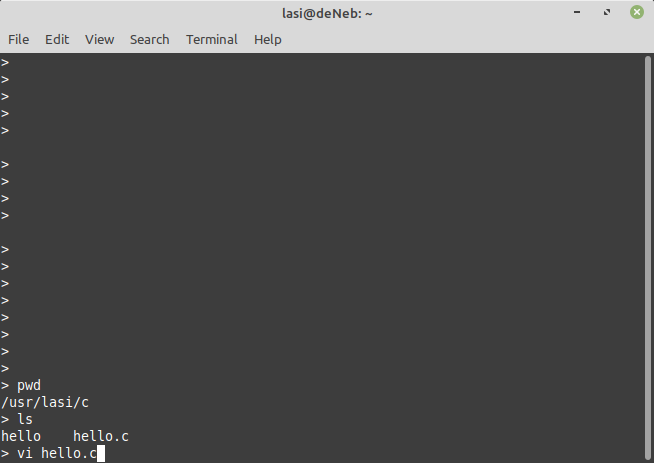
Min PiDP11/70 minidator i form av en modern mikrodator av typen Raspberry Pi model 3B. Notera att jag inte kör på den snabbaste varianten av Raspberry Pi. Valet av maskin att emulera PDP11 på gjordes utgående från vad jag råkade ha i miljonlådan … Raspberry Pi ligger på en fusklapp med kommandon man behöver för att använda den klassiska Unixeditorn ”vi” beskriven nedan.
Ett första test av en okänd dator och ifrågavarande dators programvara är ofta att skriva ett mycket kort program, kompilera det och sedan köra det. Sekvensen testar på ett allmänt plan att själva maskinen är någorlunda vettigt konfigurerad, det finns en fungerande text editor, kompilator (eller t.ex. basic tolk) samt förbindelse till bildskärm och tangentbord fungerar.
Jag har kört BSD Unix version 2.11 på min PiDP11. Alla någorlunda färska Unixvarianter är skrivna i programspråket ”c” och motsvarande kompilator heter cc (c compiler). I ett system som kör Unix brukar det alltid finnas en text editor som heter ”vi”. Editorn ”vi” är urgammal men förvånande kraftfull om användaren känner till den. Utmärkande för vi är att den är modal d.v.s. den har en kommandomod och en insättningsmod. I kommandomoden kan man med kursortangenterna och via andra tangentbordskommandon flytta sig i texten, ta bort text, söka text, byta ut text etc. Då man vill skriva text går man in i insättningsmod med kommandot ”i”. Då man vill tillbaka till kommandomoden så trycker man på ”ESC” tangenten.
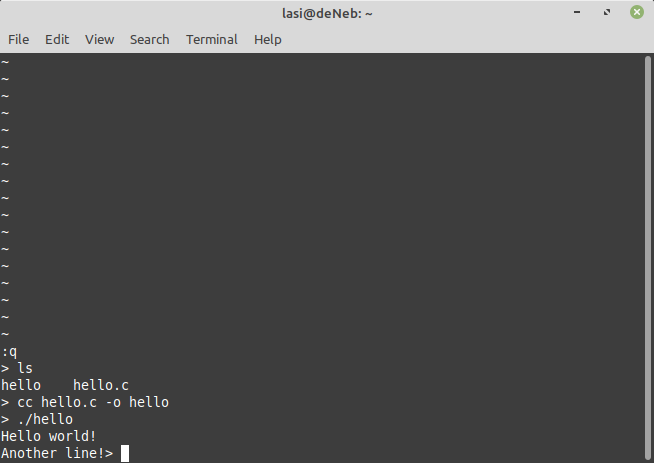
Man sparar texten med kommandot ESC :w .
Man kommer ut ur programmet med kommandot ESC :q .
Avslutning så att texten sparas kan göras med kombinationen ESC :wq .
Att tvinga stängning av programmet kan man göra med ESC :q! .
Många Unixanvändare uppfattar att det enda ”vi” kommando man behöver känna till är ESC :q eftersom ingen människa med förståndet i behåll vill göra något annat än att snabbt ta sig ur editorn.
Terminalfänster från min bordsdator deNeb över nätet ner till PDP11/70. Programmet hello.c i listningen är skrivet med vi-editorn beskriven ovan.
Vi startar vi-editorn med kommandot ”vi hello.c” och kan då studera själva programmet som innehåller två utskriftskommandon som skriver ut textraderna
Hello world! Another line!
Vi kompilerar programmet till körbar form d.v.s. maskinspråk med kommandot:
cc hello.c -o hello
Programmet körs med kommandot:
./hello
Och resultatet blir:
Kompilering av programmet hello.c . Vi ger tilläggsinformationen -o hello åt kompilatorn för att lagra resultatet i den körbara filen ”hello”. Standardnamnet på resultatet av compileringen skulle ha varit a.out vilket blir onödigt kryptiskt. Det körbara programmet körs därefter med kommandot ./hello . Orsaken till att jag skriver ./ före hello är att jag säger åt systemet att jag vill köra det program ”hello” som finns i den katalog i vilken jag befinner mig för tillfället. En Unix maskin brukar konfigureras så att man inte av misstag kör program i den katalog där man jobbar.
Jag nämnde ovan att många moderna Unixanvändare anser att det enda vi-commando man behöver känna till är ESC :q så att man med äran i behåll kan ta sig ut ur editorn. Problemet blir då hur jag skall skriva program om jag inte vill använda vi. Alternativet i 211BSD Unix på min PDP11/70 är editorn ”jove” som jag personligen har samma relation till som ”vi” d.v.s. jag vill ut ur den så snabbt som möjligt. Lösningen är naturligtvis att sätta upp kommunikation mellan min normala bordsdator eller laptop rill min PDP11 och då använda en modern editor i den moderna maskinen för att sedan flytta över program för kompilering på PDP11. Olika processer för att flytta över data mellan maskinerna presenteras i nästa avsnitt.
Dessa funderingar skrev jag som ett Facebook inlägg men de kan eventuellt intressera någon läsare på bloggen varför jag kopierar över inlägget också hit.
Jag bekantar mig med hur det känns att köra en dator från mitten av 1970-talet. Maskinen är en Digital PDP-11/70 minidator som kostade ca. $14000 då jag var en fattig student på Helsingfors Universitet. Det är fråga om en relativt sen variant med mycket centralminne som vid denna tid var RAM och inte ferritkärnminne.
Mycket centralminne i maxkonfiguration betyder 4 megabyte minne vilket dock skall jämföras med IBM:s första PC som kom ca. 10 år senare och rätt länge hade en max konfiguration på 640 kilobyte d.v.s. 1/6 av PDP-11. PDP-11 kördes ofta med tidsdelning d.v.s. flera terminaler var kopplade till samma maskin och flera personer kunde alltså samtidigt dela på maskinen.
Då jag i början av 1980-talet fungerade som data-assistent på Ammattikoulujen opettajaopisto i Tavastehus så hade man en, om jag kommer rätt ihåg, Eclipse Nova minidator (motsvarade ungefär PDP-11) som en hel dataklass i den tekniska skolan bredvid kompilerade Fortran mot … 20 elever per klass. Resultatet var att maskinen kroknade d.v.s. man kunde vänta flera minuter på något livstecken på den egna terminalen men maskinen kraschade inte! Resultatet var att jag skrev en del program på en åtta bitars CP/M maskin (som ungefär motsvarade en Commodore 64) som var härlig att jobba med eftersom jag hade tillgång till den helt ensam.
Min PDP-11/70 kostar idag ungefär 50E. Maskinen emuleras i en Raspberry Pi model 3 med 1 Gigabyte minne och 16 Gigabyte ”skivminne” på ett mikro sd-kort. Vid den här tiden hade en hårdskiva typiskt en kapacitet på 5-10 Megabyte d.v.s. 1/1000 av Raspberry Pi:s mikro SD korts kapacitet. Den lilla Raspberry Pi maskinen har en kapacitet som man sannolikt endast kunde drömma om på Tekniska högskolan på den tiden. På SD-kortet ryms mängder med operativsystem och program för PDP-11.
För tillfället kör jag BSD 2.11 från slutet av 1980-talet. Som linuxanvändare är det inget problem att köra BSD-unix. Kommandona, då man kör i terminal, är de samma. Ett grafiskt användargränssnitt saknas men jag kan köra grafiska program i en emulerad vektorgrafisk terminal på Linuxsidan i ett fönster.
Jag jobbar mot PDP-11 så att jag från min vanliga dator loggar in över nätet med ssh. Till planerna hör att då nästa sats komponenter fås fram så bygger jag en frontpanel med blinkande ledar med plats för Raspberry Pi. Det är främst strömbrytarna på fronten som ger problem, de är specialkonstruerade för den här byggsatsen för att möjligast väl matcha den ursprungliga modellen. Det är intressant att se att emuleringen är så exakt att det är möjligt att via ett adapterkort använda ursprungliga kort för en riktig PDP-11. Man har t.ex. kopplat in ett ursprungligt kärnminne (ferritringminne) och kört program från detta.
Man får en bild av den extrema utvecklingen på datorområdet då man jämför en modern Raspberry Pi med PDP-11 (jag använder en äldre Raspberry Pi modell 3 som jag råkade ha liggande). Raspberry Pi har fyra processorkärnor med ordlängden 64 bitar jämfört med PDP-11 som hade 16 bitar. Ordlängden som sådan betyder att RPi är kanske 4x effektivare och då vi har fyra processorer i RPi så kan processorn utföra 4x mera arbete.Ursprungligen så körde PDP-11 med en cykeltid på 800 ns vilket betyder en klockfrekvens på ca. 1,25 MHz vilket skall jämföras med RPi som klockas ca. 1000 ggr högre. Jag nämnde att PDP-11/70 hade ett maximalt minne på ca. 4 megabyte vilket skall jämföras med dagens RPi modell 4 som har 4 gigabyte (1000 ggr mer).
Om vi lägger ihop skillnaden mellan dagens 50Euros RPi och gårdagens $14000 minidator så ser vi att RPi totalt sett har en kapacitet som är ungefär 4x4x1000x1000 = 16 000 000 större än gårdagens PDP-11/70. Vi förstår också hur stor kapaciteten hos en Raspberry Pi är idag då vi noterar att jag kör Linux på RPi med grafiskt användargränssnitt och under Linux på RPi kör PDP-11 emulatorn SIMH som alltså låtsas vara en äkta PDP-11/70 och på den emulerade PDP-11/70:an kör jag BSD Unix v. 2.11. Den emulerade PDP-11/70 kör med ungefär dubbel hastighet mot orginalet!
En annan intressant jämförelse är att en normal Android mobiltelefon har ungefär samma hårdvara som en Raspberry Pi (eventuellt något bättre). Mobiltelefonen har alltså en total beräkningskapacitet som är miljoner gånger större än hos 1970-talets minidator. Största delen av processorkraften i dagens datorer/telefoner bränns dock på all världens bling bling och gårdagens maskin känns förvånande OK bara man inte tvingar den att rita ett grafiskt användargränssnitt med halvtransparenta fönster etc.
Jag kör ”adventure” som är ett textbaserat spel med något som påminner om Morias grottor i Sagan om ringen. Programmet körs under UNIX (BSD 2.11 som de facto är detsamma som BSD 4.3 med alla PDP-11 upgraderingar). Fönstret finns på min vanliga bordsdator som kör Linux och jag kopplar upp mot PDP-11/70 över nätverket med ssh.
Dagens ”Minidator” en Raspberry Pi model 3 emulerar gårdagens mycket använda Minidator PDP-11/70 i dubbel hastighet. Notera att det inte finns någon fläkt då Raspberry Pi förbrukar endast ca. 5W. Orginalet d.v.s. den riktiga PDP-11:n var högljudd eftersom hela maskinen ursprungligen var byggd från diskreta TTL-kretsar med mycket låg integrationsgrad. Senare modeller av PDP-11 hade processorer integrerade i en eller ett litet antal kretsar. Med högre integrationsgrad så minskade också strömförbrukningen.
Några källor:
Om någon är intresserad av att försöka sig på lödning så är detta ett relativt enkelt projekt: